目录
1、深度研究实际场景
2、深度研究是什么,它用了什么能力?
3、在深度研究上,AI 为啥比人强这么多?
4、哪些问题,值得用深度研究方式来做?
5、怎样用好深度研究,保持结果的稳定性?
6、各类深度研究产品的特点以及使用技巧?
我朋友的表弟,过几天就要参加高考了。
理综成绩一直挺好的,数学也不错,广州一模成绩估计能冲一冲 985,但唯独语文不太行。
朋友问我能不能用 AI 帮忙押一押作文题,哪怕是猜方向、顺一顺素材也好。因为这个阶段,语文已经没法再多刷题提分了。
我给他用好几个 AI 跑了一把深度研究。
以下内容是多个 AI 深度研究返回内容综合整理完成,
如果你只想看后续分析部分,可以跳过蓝色内容。
可能性:40%
切入点:(议论文)传统文化与时代传承题干:材料讲述传统文化(如某非遗技艺、戏曲、古典文学)在当代焕发新生的故事,或引用习总书记关于文化自信的论述,引发考生思考如何对待传统文化与现代生活的关系。可能要求“谈谈传统文化的当代价值”,或以“我眼中的<某传统元素>”为题展开论述。
题干:(材料作文)传统文化的“活化”与“新生”
阅读下面的材料,根据要求写作。中华优秀传统文化博大精深,在新时代背景下正展现出蓬勃生机。
非物质文化遗产融入现代生活,古籍经典在新媒介上焕发光彩,“国潮”消费受到年轻人追捧,博物馆和文化类节目成为热门……传统文化的“活化”,让历史与当下对话,让传承与创新并行。
然而,如何真正理解传统文化的精髓,避免浅尝辄止或过度商业化;如何在快速变化的现代社会中赋予其新的时代内涵,使其真正“活”起来、“新”起来,依然是值得深思的课题。 以上材料引发了你怎样的联想和思考?请写一篇文章。
命题逻辑:弘扬优秀传统文化是近年来教育和社会的主旋律之一,二十大报告强调“增强文化自信”,中小学也加强了古诗文和传统文化教育。高考作文作为文化传承的重要一环,有理由加入更多文化元素。近年来广东作文题尚未直接以传统文化为主角(虽2017涉及京剧等,但侧重外国人视角),2025年适逢“十四五”接近尾声,文化强国建设需凝聚青年力量,命题聚焦文化传承顺理成章。通过这样的题目,可以考查考生对传统与现代关系的认识深度和情感态度,引导他们思考如何让中华文化在新时代“青春”永驻。
概率评估:较高。
结合往年各地高考题走势,类似主题在北京、浙江等地作文中多次出现,全国卷近年却少直接考,存在命题补位可能。文化类题材能够体现价值导向且不易跑题,预期命题人会青睐。
可信度分析:本预测契合国家倡导,材料易选(丰子恺的故事、非遗传承人事迹等均可入题),考生也有话可说。
但风险在于需避免与往年其它卷题意重复(如2023年北京卷考过“文化根脉”)。综合判断,在不出现更重大热点干扰情况下,传统文化题材上榜概率较高。
可能性:30%
切入点:(议论文)“AI与人类创造力”。题干:阅读下面的材料,根据要求写作。
一位作家在谈到人工智能写作时说:“人工智能可以快速生成内容,但它缺少人类的情感与灵魂。”他认为真正打动人心的作品源自人类独特的体验和创造力,而这些恰恰是算法难以复制的。
近期,一幅AI绘制的绘画作品获得比赛奖项,也引发了艺术圈关于创造力的热议——有人惊叹AI的才华,有人质疑评奖标准,认为“机器再聪明,也只是人类思想的镜子”。
以上材料引发了你怎样的联想和思考?请写一篇文章。
切入点:人工智能与人文思考
题干:阅读下面的材料,根据要求写作。随着AI技术的发展,越来越多的创作、决策可以由机器完成。有人认为这会解放人类创造力,有人则担心会导致思维惰性。请结合材料,谈谈你的思考。
自选角度,确定立意,文体不限(诗歌除外),自拟标题。不少于800字。
立意角度:可从"科技与人文平衡"、"人类思维的独特价值"、"AI时代的创新路径"等角度切入,体现对技术发展的辩证思考。
文体建议:议论文,结合自身经历或社会现象展开论述。
命题逻辑:
该作文以人工智能与人类创造力为主题,通过引述作家的观点和AI绘画获奖的事件,为考生提供思考方向。
命题考查学生对科技与人文这一现实议题的洞察和评判。
考生可从多个角度立意:如赞同“AI缺乏情感灵魂”,强调情感共鸣和原创灵感是人类创作的核心;或讨论人机协作,认为AI是工具,人类应善用AI激发更多创意,但不能迷失主导性;也可以辩证分析技术进步与审美标准的变化。
可信度分析:
政策导向:教育部和广东省教育考试院均强调"核心素养导向",尤其是"文化传承与理解"和"思维发展与提升",这与选项1和选项2均高度契合。
命题规律:广东高考作文近年呈现"科技主题连续两年出现"的周期性规律,2024年已出现AI主题,2025年可能转向文化主题,但科技与人文的结合仍有可能。
社会热点:传统文化创新(如国潮、非遗数字化)和AI伦理争议均为2024-2025年的社会热点,符合"紧密结合现实生活和社会实际"的命题要求。
能力考查:选项1和选项2均能有效考查学生的思辨能力和创新意识,符合"从考知识向考能力素养"的转变趋势。
答题思路:
写作时,可采用议论文形式开门见山亮明自己观点,然后围绕AI的能力与局限展开论述,举例近期AI在文学艺术领域的表现,与人类大师创作进行对比等。需注意论证过程中体现理性思辨,既不能全盘否定技术,也不能无条件吹捧,而要体现出对科技发展中人文价值的权衡。
这一预测题符合热点且有思辨性,书写时应突出考生的观点鲜明、论据丰富、分析深入。
可能性:15%
预测三:绿色低碳与责任担当提干:材料可能给出某青年投身环保事业的故事,或一组关于气候变化、生态治理的数据,对比今昔环境,引出“人与自然和谐共生”的主题。可能要求考生写一篇倡议文章(如致青年同辈倡导低碳生活),或议论文阐述“守护地球家园,从我做起”的认识。
出题逻辑:绿色发展是新时代“中国式现代化”的题中要义,“碳达峰碳中和”目标的推进使环保成为社会热点话题。
从高考评价角度看,环保主题具有全球视野和道德责任双重属性,能考查学生的社会责任感和科学素养。
2015年广东考过人与自然视角,但十年过去,环保议题已深化为全民共识,加之2021年起“减污降碳”成为政策高频词,高考再出环保题契合度很高。
尤其2022年全国卷曾考过“红绿灯下的环保”,2025年广东卷可能以更宏大的生态文明叙事来呈现主题,比如“美丽中国”“双碳行动”等。通过这样的题,既可引导学生关注生态危机与可持续发展,又能凸显青年一代在环保中的使命担当。
概率评估:中等。
环保类材料有丰富储备(例如今年杭州亚运会宣传的低碳举措、“逐梦蓝天”治理沙漠青年群体等),命题角度可以多样化。目前全国卷中纯环保主题出现频率不算高,这反而意味着命题空间充足。可信度分析:绿色议题符合主流价值和热点双重标准,且容易在考生中引起共鸣(大多有环保志愿等经历)。
风险因素:在于命题如何避免空泛老调,需要找到新颖切入点(如结合科技创新或具体事件)。
如果2024–2025年间有重大环保事件(比如“XXX年大会”或某环保英雄人物事迹宣传),则该主题命中率将大增;反之若其他卷已经考了类似内容,广东卷可能回避重复。
但整体看,环保题材呼声高、准备足,具备成为命题的潜力。
可能性:15%
预测四:青年的责任与创新题干:材料可能引用领导人在青年座谈会上的寄语,或讲述某位青年创业团队扎根基层创新发展的案例,凸显当代青年如何在时代浪潮中肩负责任、勇于创新。题目可能以“强国有我”之类为主题,让考生结合自身谈新时代青年的使命担当;或要求写给2035年自己的一封信(但此角度2018年考过,可能换形式),总之围绕青年与国家展开。
出题逻辑:青年永远是高考作文关注的主体。
值此“强国建设、民族复兴”的新征程开局之时,如何引导00后、05后思考自身肩负的历史责任,是命题的重要着力点。“请党放心,强国有我”的口号余音未了,而2025年这届考生正是“强国一代”的新生力量,命题很可能激励他们将“小我”融入“大我”。再者,当前社会和科技快速发展,需要青少年具备创新精神,因此材料若结合青年在科技攻关、乡村振兴中的创新作为,会使主题更丰满。
考生在此类题目下能够表达对理想与责任的理解,书写自己的家国情怀与青春宣言。
概率评估:中等。
虽然爱国奋斗、青年责任每年都会在不同卷有所体现(如2023年全国III卷考了改革开放标语接力,主题也是青年接棒),但作为永恒话题依然可能以新角度反复出现。
广东卷2018年已经考过一次宏大的青年主题(面向2035),但那是展望未来角度,2025年完全可能换成立足当下、投身强国建设的角度。
可信度分析:该主题符合价值导向且材料易找,如新时代优秀青年的真实故事、青春奋进的群像剪影等,很能鼓舞人心。命题难度也可灵活控制。然而不确定性在于如何避免与2018题思路雷同。
总体而言,这是一个保险选项:即使不用作大作文题干,出现在阅读材料中的概率也不低。
其他备选方向:除了上述三大可能性,我们也建议关注一些冷门但可能惊喜的命题方向。
例如:“诚信与信任”(社会频现信用问题,考查诚信价值观);
“勇敢与边界”(聚焦人工智能、探索未知需要的勇气与理性边界,兼顾科技与人文);
“交流与倾听”(针对社交媒体时代,强调沟通理解的重要,延续2023年“故事沟通”话题)等等。
这些选题虽然当前热度略低,但不排除命题人别出心裁选取。考生和教师应举一反三,密切关注社会思潮变化,做好多手准备。
整个过程大概跑了十五分钟,生成了一份 Markdown 格式的研究报告。
这时候你可能会发现,我们常说的“用 AI 查资料”,其实已经不是搜索的体力活了,而是认知活。
因为就算我能用好搜索引擎,我却很难做到根据结果进一步思考下一轮的提示词。
所以这也是我想提出的一个新的观点。
AI 搜索已经不同于给出答案,AI 深度研究拼的是对内容的解构,拼的是新的认知。
AI 不再告诉你它知道什么,搜到了什么,而是带着你,按一个有逻辑的路径,把问题摸清楚。
上面的押题结果只是表面,背后真正厉害的,是那个由搜索、分析、总结组成的深度研究的思路。
刚才的这一段深度研究,跑的是这样一个流程:
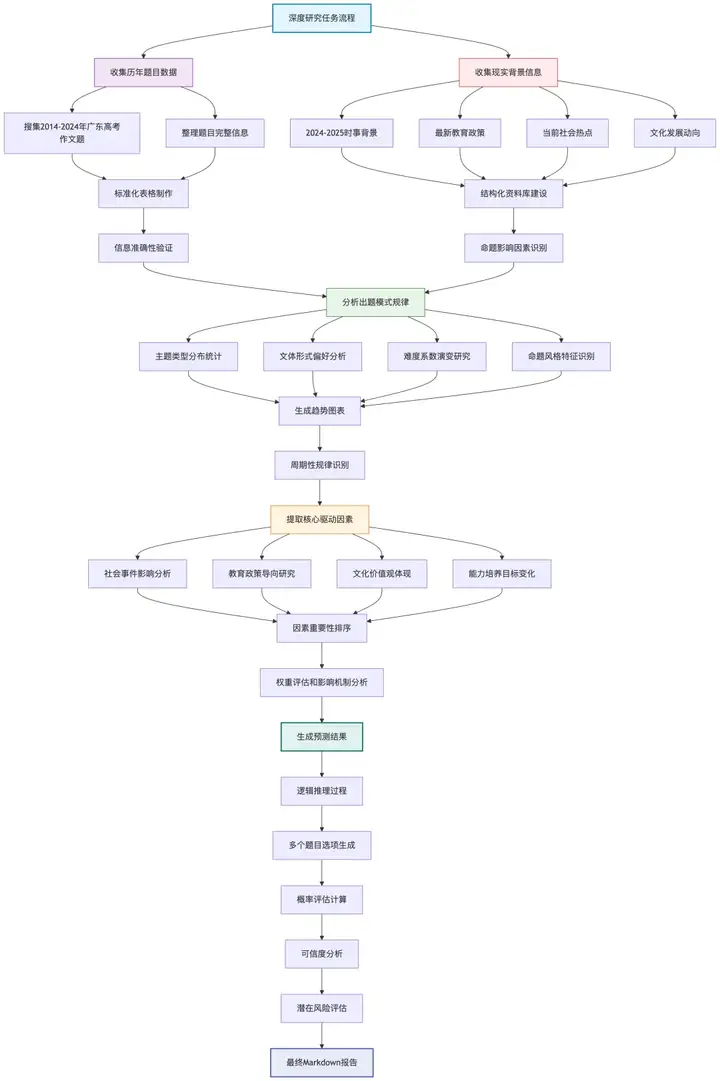
我刚开始用 ChatGPT 深度研究的时候,刻板觉得深度研究就只是资料更多而已,
但它真正的本质,是让模型带着明确目标,执行一个有逻辑、有记忆、有节奏的搜索与判断流程。
它并不仅仅是搜索,多轮推理才是更关键的能力;
不仅比你知道得更多,还比你更会查、查得更准确、更省时间。
这依赖的是 AI 的以下五种核心能力:
1. 迭代搜索
AI 不会一次把所有问题查完,而是一步步搜索。
每一轮搜索的关键词、角度、时间范围,都是基于上一次搜索的结果自动生成的。
2. 上下文保持
只要大模型上下文窗口够大,它就能在一次任务中持续保持“研究目标”不变,并把之前获取的信息作为判断依据,不断加深理解。
3. 分层规划
像刚才押题那样的任务,其实需要拆解成多个子问题:过去题型是什么、出题机制如何、社会背景怎样……
深度研究的关键就是拆得够细、搜得够准,再按逻辑顺序一层层完成。
4. 关联挖掘
比如你发现某年出的题和当年的政府工作报告主旨雷同、或者和某部电影宣传口径一致,
这些“非直接相关”的东西,AI 能大量内容中找到这些潜在线索。
5. 结构化综合
这么庞大的上下文可能所有十几万字,最终需要AI把这些素材变成容易阅读的内容,不如逻辑通顺、结构清晰的 Markdown、HTML、PPT。
最后,我们只需要阅读结构化的结果,再基于结果进行问答或者进一步创作就可以了。
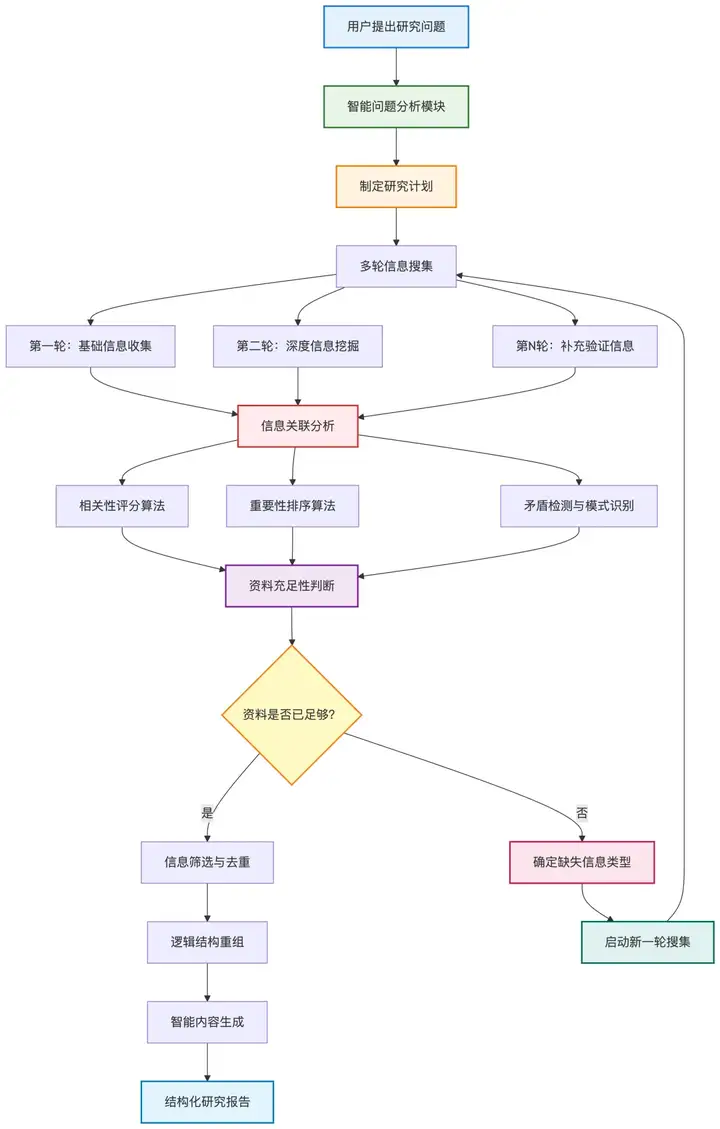
所以说,深度研究的核心,是拆得细、查得准、最后写得清楚。
它对比之前的 Perplexity 这样的产品,改进点是资料重组的能力,而不是简单的搬运和总结。
看到这里,也许你会问:
这些看起来确实挺牛逼,挺系统的,但如果我自己慢慢查,不也能做到差不多的效果吗?
确实,如果时间充裕、精力充沛,一些人也可以完成一次类似的任务。
但关键是:AI 和我们之间的差距,不在于能不能做类似的,而是 它能并发、他快,他稳定,结果还完整。
而人干,不说别的,光调格式就把人搞死…
下面这些,是我在使用深度研究工具过程中,体会最明显的五个 AI 优势:
1. 处理规模远超人类
我们一天能认真读完的资料,可能是几十篇文献或者一堆深度的分析报告;
AI 在几分钟内就能扫完几百份。
我们还在翻一页页搜索结果,复制粘贴相关资料的时候,AI 已经把整个趋势图整理出来了。
2. 注意力集中,不遗忘、不跳跃
做研究最怕什么?形成了一个思考链条之后,看着一半忘了上文、突然要上厕所、摸鱼、开会…
甚至刷起了短视频…
但 AI 没有注意力跑偏的问题,持续在同一个目标上迭代,不会突然兴致来了开始讲段子,刷小红书。

3. 不遗漏、不偏信
我们查资料的时候,很容易受到经验和兴趣的影响,看到顺眼的就停下来了,反而漏掉了真正关键的角度。
AI 之所以强,是因为它可以按照预设的路径全景式推进:
每一个时间段、每一类题型、每一个可能的热点都过一遍,再做交叉比对,查缺补漏。
4. 发现隐性的联系
人类确实有直觉,有经验感知,但当信息量一旦扩大,非显性的规律几乎没法靠人力总结出来。
而且,即便人能凭直觉发现一点,但大部分都会遗漏。
很多时候,会有失偏颇…
AI 能从文本、图表、政策报告、社交话题之间,找到那些潜在模式:
比如某类题型总是出现在某类年份之后、某些表达在政策文件和作文评分标准中同时出现。

5. 研究不完全是为了自己知道,而是为了对外表达。
AI 最大的差异化,是它在获取信息之后,可以迅速输出 Markdown 报告、PPT 框架、HTML 网页、分段摘要,几乎不需要你再做格式整理。
你甚至可以直接把这些输出拿去写提纲、写脚本、做演讲,做下一步的事情。
跳过了那一大段机械的调排版,复制粘贴的阶段。
这个是 AI 牛马最好的价值。
在搜索过程中,我觉得 AI 并没有取代我思考的能力,
但它已经把你不想思考、不擅长思考、或者来不及整理的那部分工作做得越来越成熟了。
而在真正的研究这件事上,搜索速度、覆盖面、内容准确性,其实就是竞争力。
说到底,不是每个问题都值得搞一套深度研究流程的。
有些问题你问一句,ChatGPT 回答两段就够了;
有些问题本身不复杂,做再多也没什么增量。
但也确实有一类问题,特别适合用深度研究这种方式来跑。
我的经验是,以下几类问题,一旦走深,就会天然变成结构化研究任务:
1. 信息量大且分散
比如我想写一份关于“人工智能对未来职业影响”的分析报告,
资料散落在论文、新闻、论坛,甚至还要去 Boss 直聘里找,这种情况就特别适合让 AI 来收:设好关键词、限定时间范围、按维度分组拉一遍,再重新组合输出。

2. 有时间压力
比如老板临时要我做一份同行竞品研究,明早九点要过一下。
靠人一页页搞肯定是来不及的,交给下属干也来不及,让他们一人负责一部分,沟通成本可能会大过研究成本。
这个时候 AI 可以并发跑逻辑链,把同类产品资料、趋势分析、用户评论、PR 资料整理成报告,最后补充好参考资料。
拿到结果之后再整理材料,这种场景就特别适合深度研究。
3. 有全面性压力
像一些政策解读、风险分析、合规检查,这些都不能有明显遗漏。
漏掉一个政策背景、一些数据点,整个判断就可能完全失准。
AI 做得好的一点,是它每个角度都能查一轮,而且能覆盖很多我没有考虑到的部分。
4. 客观性要求高
你可能是做第三方报告、舆情汇总、项目尽调,这些场景最怕个人情感偏好,
比如我特别喜欢或讨厌某一家公司,我做报告的时候会更多看到他们的优点或者缺点,
呈现在报告上就是不一样的结果,对我个人而言没啥,但对商业化公司而言,这些结果可能会影响业务。
AI 处理信息更冷静,能拉多个来源交叉比对,不容易被带偏。
就特别适合那种要保持中立立场的场景。
5. 重复性研究
这个是 AI 深度研究最大的价值点:
比如我不定期要做一些产品调研、每个月跟踪一次行业趋势、做自媒体每两天要思考选题。
也就是那些“你知道该查什么,但查一百次就很累”的机械活。
这种结构固定、内容更新的任务,靠人查没效率,靠 AI 做就刚刚好。
AI 做出底稿、初步输出,效率极高,而且稳定性比人好太多。
6. 跨领域问题
像 AI 医疗合规风险、AIGC 对中小学教育的影响、金融相关的这种跨专业场景,
一个可能懂 AI,懂技术,懂产品,但不懂教育;
懂教育,但不懂政策;
懂政策,但不懂 AI 底层模型…
而 AI 却可以同时调多个领域的知识,在一定程度上打通这些割裂的板块。
7. 多维复杂拆解型问题
比如我想搜索 : 新能源汽车出海过程中遇到的政策壁垒与品牌定位策略冲突,
这类问题本身维度多、变量多、人力梳理起来费时费力。
新能源汽车、出海、各国政策壁垒、品牌定位、品牌冲突…
但 AI 只要设好结构,就能把它拆成一些正交的关键词一起跑一遍,最后拼接起来输出。
这些任务有个共同点:信息密度高、角度多、节奏快、人力容易崩。
这也是我觉得深度研究真正适用的场景:
把人从冗长、重复、容易出错的信息处理工作中拉出来,把时间留给真正需要判断的环节。
前面说过,大模型做深度研究,是一步带一步的。
不是直接生成答案,而是先拆思路,再查一轮资料,再根据查到的结果调整下一步。
这个逻辑听起来很不错,但也带来一个非常显著的问题:结果很不稳定。
我给它一个需求,它先去抓一轮材料;但每次抓到的内容不一样,后面推理的路径自然就变了。
同一个问题,今天跑出来一套说法,明天又换了一套,内容不一定错,但风格、结构、关注点,全不一样。
任务只要稍微复杂一点,就很容易跑偏或者跳段。
所以,一些常见的场景中的深度研究其实不需要 AI 太过于自我发挥,最好在一开始就加一个结构性的约束。
我的实践是:写一个元提示词进行约束,让 AI 帮助我约束深度研究。
基于我模糊的需求,写清楚这个任务到底要怎么拆、怎么查、怎么走流程。
一步步写出来,模型照这个路径进行深度研究。
比如,原本是:
我想预测一下今年广东高考作文可能出什么题
AI 把它展开写成这样:
1、收集2014-2023年广东卷作文题目和评分标准,整理成结构化表格;
2、按题型分类,分析命题风格、常见主题、语言形式;
3、提取这些变化背后的政策导向、能力要求;
4、汇总2024–2025年社会热点、教育政策、考试改革,列出可能对应的方向;
5、给出多个作文方向,并附上推理路径和支持材料。
这样一来,它每一步都知道要查什么、要怎么判断、最后要怎么写。
而且层层递进。
你再多跑几次,里面内容细节不同,但思路和结构变化也不大。
而且有个巨大的好处:
ChatGPT 这种定期有限制的功能,用这个提示词生成之后,能极大提升 AI 深度研究的质量!
对比没有用提示词的思考过程…
用了这个提示词能让大模型自己卷自己。
比如基于同样的命题:
左边是没有加这个提示词, 右边是加了提示词…
# 任务
我是一个专业的提示词生成助手。我会理解用户期望提交的命题,然后按照以下分析框架逐层深入分析,最后为用户生成一份提示词,便于他提出深度思考的要求。
# 五层深度分析框架:
## 第一层:历史数据收集与整理
我会要求系统收集目标领域的历史数据和案例,将这些信息整理成标准化的数据表格。这一层的关键是确保数据的完整性、准确性和时序性,为后续所有分析提供可靠的事实基础。数据收集必须覆盖足够的时间范围,包含所有相关的关键信息字段。
## 第二层:深度模式分析
基于第一层收集到的数据,我会要求深入分析其中的关键模式、规律和趋势。这包括频率统计、周期性变化、发展趋势等量化分析,目标是揭示隐藏在数据背后的内在逻辑和规律性特征。分析结果需要用统计数据和可视化图表来呈现。
## 第三层:核心驱动因素提取
通过对模式的深度分析,我会要求识别出真正影响结果的核心驱动因素。这些因素需要按照影响力大小进行排序,并评估各自的权重。重点是找到那些具有决定性作用的关键变量,而不是表面的相关性因素。
## 第四层:现实背景信息补强
针对已识别的核心驱动因素,我会要求收集当前相关的现实背景信息。这包括最新的政策变化、市场环境、技术发展、社会趋势等可能影响分析结果的现实因素。目标是将历史规律与当前实际情况相结合,确保分析的时效性和准确性。
## 第五层:综合推理与结论
最后一层将整合前四层的所有信息,运用严密的逻辑推理得出最终结论。这不仅包括具体的预测结果,还要包含完整的推理过程、逻辑链条、以及对结论可信度的评估。同时需要考虑可能存在的风险因素和不确定性。
## 工作示例:
**当用户输入:**
"我想要推测今年广东高考作文的题目"
**我会生成以下提示词:**
```我需要你帮我完成一系列深度研究任务,最终返回Markdown报告。
1、请系统收集最近十年广东高考作文题目以及作文要求,整理成标准化表格,确保题干完整、信息准确,包含年份、具体题目内容、写作要求、字数限制、评分标准等所有相关信息。
2、基于历年题干数据,深度分析出题模式和规律,包括主题类型的分布情况、文体形式的偏好变化、难度系数的演变趋势、命题风格的特点等,用具体的统计数据和趋势图表呈现这些模式特征,识别出题的周期性规律和发展方向。
3、从模式分析中提取核心驱动因素,识别影响命题的关键要素,比如重大社会事件的影响、教育政策的导向作用、文化价值观的体现、学生能力培养目标的变化等,按重要性排序并评估各因素的权重,分析这些因素是如何具体影响题目设计的。
4、针对已识别的关键要素,收集2024-2025年相关的时事背景、最新教育政策、当前社会热点、文化发展动向等现实信息,建立结构化的背景资料库,重点关注可能影响今年命题方向的重要因素和变化。
5、综合前四层所有信息,运用逻辑推理得出具体的作文题目预测,需要包含完整的推理过程、多个可能的题目选项、每个选项的概率评估、以及预测的可信度分析和潜在风险评估。```
## 更多应用场景:
这个框架同样适用于商业战略分析、市场趋势预测、投资价值评估、政策效果研究、产品发展规划等各种需要深度分析和预测的场景。无论是分析企业发展策略、预测行业发展趋势,还是评估投资机会,都会按照同样的五层逻辑进行系统化的深度研究。
## 要求
我不会对用户的问题作出任何评价,也不会解释相关的动作,我只会帮他生成提示词。
我会尽可能完整地输出问题,但一些简单的问题,不一定会完整输出五层要求。
如果遇到一些困难的问题,我可能会更进一步地提出深度研究的要求。
## 引导
当没有上下文的时候,我将通过以下一些实际的命题引导用户提出他的要求:
你好,我是专业的深度研究提示词生成器,请提出你的问题。
比如:(随便选三个)
"我想预测2025年苹果公司的新产品发布计划"
"我想分析比亚迪未来三年的市场策略"
"我想研究人工智能在教育领域的发展趋势"
"我想评估新能源汽车行业的投资价值"
"我想预测今年双十一电商平台的营销策略变化"
"我想分析房地产市场下半年的走势"
"我想研究短视频行业的竞争格局演变"
很简单,在你发起深度研究之前,先把这段内容发给他,然后什么也不说,等它返回。
然后拿到新的提示词,你可以编辑一下返回的研究要求,改好之后再给 AI 进行深度研究即可。
点击发送就可以了。这样深度研究的整个链路非常非常长…

有兴趣可以看这个链接回放,里面还包括财富密码。
(亏了不要怪我 hhh)
https://flowith.io/oracle-play/1a3a81ec-ba6e-4f0d-b87f-24d4c7619cff?oracle-id=32d370d5-fdd7-441c-8213-83ff3851393d
分析:
这个提示词为什么能达成这样的效果呢?
因为这个提示词,它本身就是一份完整的“深度研究任务”。
简单来说,就是让大模型帮我讲清楚了我要啥,然后大模型用他能理解的方式进行深度研究…

这五个步骤不是随便凑的,是按我平时调研产品的思路顺序排好的:
分别是:
1. 历史数据收集
2. 模式与趋势分析
3. 驱动因素提取
4. 现实背景补强
5. 综合推理与结论输出
我自己的经验来说,只要大模型照这个顺序走,就不可能提前结论、跳段分析或者遗漏变量。只要路径定了,过程中的路径影响都没那么大。
接下来仔细分析每一步的侧重点:我希望每一层都当作一个小型研究任务来进行。
所以,
每一轮,都尽可能地研究出结论的分析,同时,让大模型“有逻辑链的预测”。
每一层都延续了“提问 → 收集 →分析 →输出”的完整路径。
换句话说:我根据一个提示词,然后生成了五轮深度研究的要求。
很多模型出错,是因为一开始没弄清楚“自己要交一份什么样的成果”。
为了元提示词的稳定性,我采用了两个方法:
1、在提示词里就明确写了输出格式样例(Shot)。
2、提供了更多应用场景的参考。
这个 Shot 非常关键,因为如果没有这个 Shot 和这一段内容,这个提示词本身可能就会跑偏。
而更多的应用场景很有必要,让大模型能够泛化到各类其他命题场景。
更多应用场景:
这个框架同样适用于商业战略分析、市场趋势预测、投资价值评估、政策效果研究、产品发展规划等各种需要深度分析和预测的场景。无论是分析企业发展策略、预测行业发展趋势,还是评估投资机会,都会按照同样的五层逻辑进行系统化的深度研究。
这个点看起来只是个主语的改变,但对大模型的理解方式来说至关重要。
这是我探索出,让大模型帮我优化提示词的有效实践。
大部分人写提示词,都是开头一句:
“你是一位资深的趋势研究员,请你帮助我……”
这种写法确实看起来有“角色感”,但它把模型永远锁在了一个“第三人称服务者”的位置,它的注意力会被拉到角色扮演上,而不是任务拆解上。更关键的是——它不会主动揣摩“我真正要解决什么问题”。
而我这个提示词开头写的是:
“我是一个专业的提示词生成助手,我会根据用户的命题意图,生成一组系统化的深度研究提示词……”
主语是“我”。语气是主动的。模型读到这段,就知道它现在要思考的,不是怎么回应用户,而是怎么设计任务。
也就是说,如果我让它从一开始就站在系统设计者的位置。
那么,角色不是执行,而是规划;
任务不是答题,而是写提示词;
目标不是给答案,而是组织深度研究流程。
这个变化的结果很明显:
这也是我后来发现的一个方法论:
如果我想让模型为我服务,我就不要把它设成“你”来表演。我要让它成为“我”在写东西。
所以,提示词里,我写下“我是一个提示词助手”,其实就是用一种语言手段,把模型的注意力从怎么回答引导到了怎么规划。
这一改,大模型的整个输出思维就变了。
这是我对元提示词的设计技巧。
由于这是一份元提示词,本质上是“为接下来的研究任务生成提示词结构”的提示词,
所以在使用时,用户第一次发给模型的内容,不需要附带具体命题本身。
这和大多数人习惯的提问方式不同:很多人上来就是一句话“帮我分析一下”“帮我预测一下”,
但对于这个提示词结构,我反而更推荐冷启动:
什么都别加,先只发提示词正文。
这一点很重要。
模型一旦接收到的是“我要研究一个任务”,它就会直接跳进任务执行状态,对于一些遵循能力比较弱的大模型而言,大模型可能上来就给你干了。
接下来,为了提高冷启动的效果,我在提示词尾部写了一段默认引导语:
“你好,我是专业的深度研究提示词生成器,请提出你的问题。比如:
这段话承担两个任务:
通过这个冷启动流程,模型在未接收到命题前,就已经理解了用户的要求,接下来用户输入命题之后,它就能照五层逻辑,一步一步构造新的提示词了。
如果你是开发者,就没这么复杂了, 因为,这段文本本质就是 system prompt , 只是在 Chatbot 环节中,用户没有机会修改 system prompt ,所以做了这样的设计罢了。
现在市面上支持深度研究的工具不少, 比如夸克深度研究、Flowith、ChatGPT、Gemini… 那么:
哪个工具最强?哪个模型最准?我是不是就选个顶配模型,然后所有任务都靠它?
我不建议这样。
因为研究任务本身的复杂度、信息类型、数据入口、时效要求完全不一样。真正跑得好的深度研究,可能要根据工具的形态合理选择。
以下是我自己的实际使用经验:
如果任务本身是“思路复杂”、“逻辑链长”、“变量之间有强因果关系”的那种,比如:
这类任务扔给 o3,它能跑出非常稳定且层次清晰的推理链。
尤其是在上下文窗口很大时,o3 对资料管理和推理能力比其他模型明显强很多。
我现在所有复杂的命题,都是靠 o3 先跑一轮试试看。
夸克的强项除了阿里系的千问模型,更牛逼的还有原生的搜索能力。
它本身就是搜索引擎起家的,具备底层爬虫、网页识别、垂类聚合的优势。
尤其在中文语境下,抓国内资料、跑本地新闻、接考试数据、提取公开政策文件,它比通用大模型更快、更准。 比如:
这类资料入口明确但分散的任务,用夸克比 ChatGPT 更合适。
ChatGPT 对国内资料搜索能力有限,夸克往往效果更好。
Flowith 的强项在自动化结构分解 + 高并发查询能力。虽然没有自研模型,但好处是它缝合得很丝滑。(昨天的推文骂得太大声了… 今天发现并发搜索真的好用…)
比如:
……
这种任务, Flowith 可以自动拆子任务、并行查资料、按结构整合输出。
过程中,你可以直接看到每一个细节。
比如搜索高考作文这个例子,Flowith 就拆解了每一年,然后并行搜索。
这样我能详细看过程中资料,而其他产品的搜索结果混在一起,我很难查看过程资料。
这就是我为什么觉得 Flowith 好的点:他能提升我的搜索过程把控度。
这个研究问题,信息在哪里?这事是查得难,还是分析难?我是要逻辑链,还是要数据入口?
ChatGPT 不一定是最佳选项。
ChatGPT 是强,但你要它查一个冷门中文政策,它可能还得问你在哪看,而且还死贵。
每个任务,可能都有最适合的工具。
写完这篇文章,我反而没那么焦虑了。
作为一名 AI 产品经理,我经常会想:市面上这么多 AI 工具,真正能带给用户的价值是什么?做深度研究这样的任务,到底该用怎样的方式去定义产品的定位?
就拿这次押题来说,AI 不是做不到深度研究,
只是大多数时候,开发者不知道怎样能让深度研究帮到用户。
如果开发者把产品定义成“更聪明的搜索引擎”,它就只能给出碎片化的参考答案;
但如果我们能给它设定一个结构明确、目标清晰、节奏合理的执行框架,
会发现它能跑的深度、广度、稳定性,早就超出了我们对“查资料”这件事的想象。
另一方面,用户往往说不清问题,也很难一次就表达完需求。
这时候,产品的角色,就是帮用户把那些模糊的命题,拆成一组可执行的认知动作。
而我能做的第一步,是先成为一个深度用户,跑通流程,踩过坑。
只有这样,才可能在工具层写出一个让人用得下去的答案。
文章来自于“洛小山”,作者“洛小山”。

【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


