前段时间,OpenAI 研究员姚顺雨发表了一篇主题为「AI 下半场」的博客。其中提到,「接下来,AI 的重点将从解决问题转向定义问题。在这个新时代,评估的重要性将超过训练。我们需要重新思考如何训练 AI 以及如何衡量进展,这可能需要更接近产品经理的思维方式。」(参见《清华学霸、OpenAI 姚顺雨:AI 下半场开战,评估将比训练重要》)
由于观点非常有见地,这篇博客吸引了大量从业者围观。
有意思的是,亚马逊首席应用科学家 Eugene Yan 最近也发表了一篇博客,专门介绍 AI 产品的评估,可以说是对姚顺雨博客的有力补充。
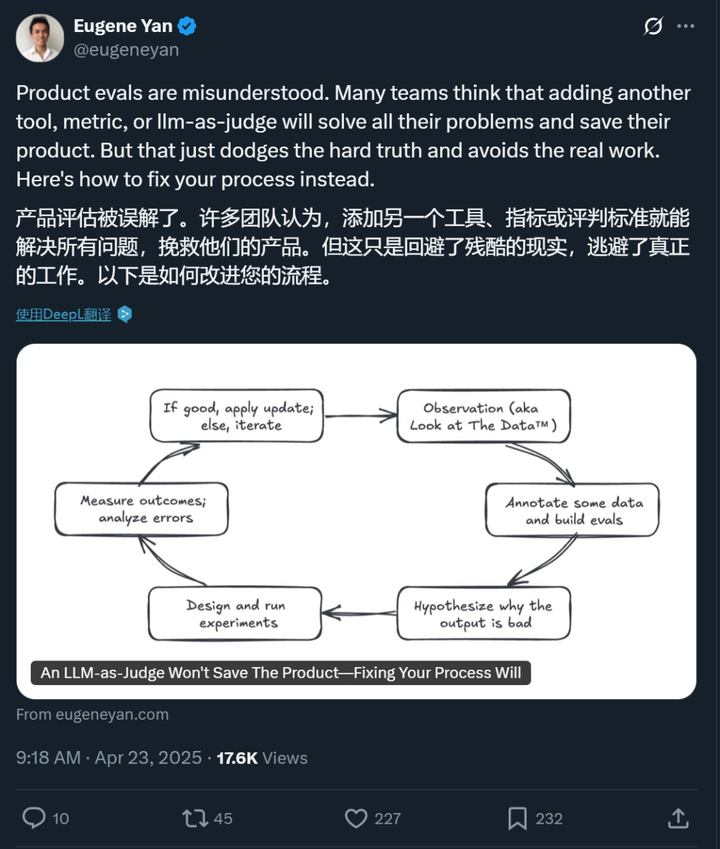
这篇博客同样得到了诸多好评。
以下是博客原文。
自动化评估救不了你的产品
你得修复你的流程
产品评估这件事,很多人根本没搞懂。总有人以为再加个工具、添个指标,或者让大语言模型当裁判(LLM-as-judge),就能解决问题拯救产品。这根本是在回避核心问题,逃避真正该做的工作。评估并非一劳永逸,也不是什么快速起效的方法 —— 它是运用科学方法的持续实践,是评估驱动开发,是 AI 输出的持续监测。
构建产品评估体系,本质上就是在践行科学方法。这才是真正的秘诀。它是一个不断提问、实验和分析的循环。
首先从观察开始,也就是「看数据」。我们要审视输入内容、AI 输出结果,以及用户与系统的交互情况。数据会告诉我们系统哪里运转良好,更重要的是,哪里会出问题。发现这些故障模式才是有效改进的起点。
接着我们标注数据,优先处理问题输出。这意味着要对成功和失败的样本进行标记,建立平衡且有代表性的数据集。理想情况下,正负样本应该五五开,并覆盖各类输入场景。这个数据集将成为针对性评估的基础,帮我们追踪已发现问题的改进情况。
然后,我们提出假设:为什么会出现这个错误?可能是 RAG 检索没返回相关上下文,也可能是模型处理复杂(有时自相矛盾)的指令时力不从心。通过分析检索文档、推理轨迹和错误输出等数据,我们能确定要优先修复的问题以及要验证的假设。
紧接着设计实验验证假设。比如重写提示词、更新检索组件或切换不同模型。好的实验要能明确验证假设是否成立,最好还设置基线对照组进行比较。
结果测量和错误分析往往是最难的环节。这不同于随意的感觉判断,必须量化实验改动是否真有效果:准确率提升了吗?缺陷减少了吗?新版本在对比测试中表现更优吗?无法量化的改进根本不算改进。
实验成功就应用更新,失败就深挖错误原因,修正假设再来一次。就在这个循环中,产品评估成了推动产品进步、减少缺陷、赢得用户信任的数据飞轮。
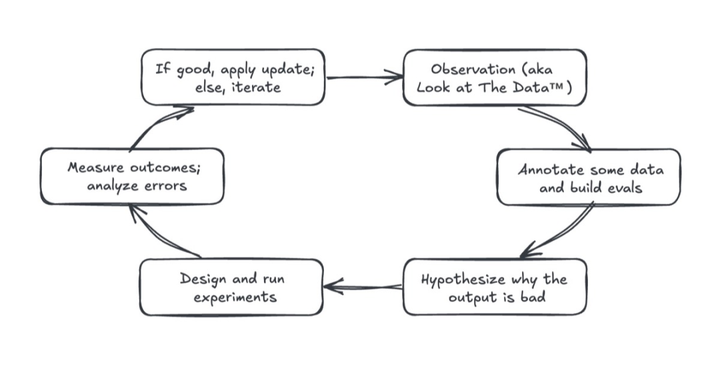
将科学方法应用于 AI 产品开发。
评估驱动的开发(Eval-driven development,EDD)能帮我们打造更好的 AI 产品。这类似于测试驱动的开发 —— 先写测试用例,再实现能通过测试的代码。EDD 秉持相同理念:开发 AI 功能前,先通过产品评估定义成功标准,确保从第一天就有明确目标和可衡量的指标。说个秘密:机器学习团队几十年来都在这么做,我们始终根据验证集和测试集来构建模型系统,只是说法不同而已。
在 EDD 中,评估指引开发方向。我们先评估基线(比如简单提示词)获取基准数据。之后每个提示词调整、系统更新和迭代都要评估:简化提示词提升了准确性吗?检索更新增加了相关文档召回率吗?还是反而让效果变差了?
EDD 提供即时客观的反馈,让我们看清哪些改进有效。这个「写评估 - 做改动 - 跑评估 - 整合改进」的循环确保了可衡量的进步。我们建立的不是模糊的直觉判断,而是扎根于软件工程实践的反馈闭环。
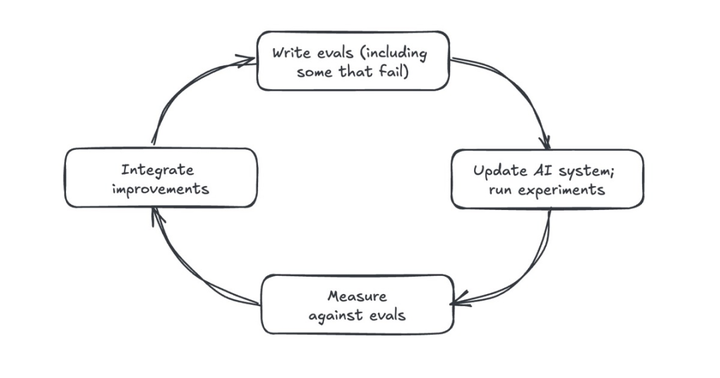
先写评估标准,再构建能通过评估的系统。
自动化评估工具(LLM-as-judge)也离不开人工监督。虽然自动化评估能扩大监测范围,但无法弥补人为疏忽。如果我们不主动审查 AI 输出和用户反馈,再多自动评估工具也救不了产品。
要评估和监测 AI 产品,通常需要采样输出并标注质量缺陷。有了足够多高质量标注数据,我们就能校准自动评估工具,使其与人类判断一致。这可能涉及测量二元标签的召回率 / 准确率,或通过两两比较决定输出之间的相关性。校准后的评估工具能有效扩展 AI 系统的持续监测能力。
但自动评估工具不能取代人工监督。我们仍需要定期采样、标注数据,分析用户反馈。理想情况下,我们应该设计能够通过用户交互获取隐式反馈的产品。不过,显式反馈虽然不那么频繁,偶尔也会有偏见,但也很有价值。
另外,自动评估工具虽扩展性强,但也不完美。不过人类标注员同样会犯错。只要持续收集更高质量的标注数据,我们就能更好地校准这些工具。保持「数据采样 - 输出标注 - 工具优化」的反馈循环,需要严格的组织纪律。
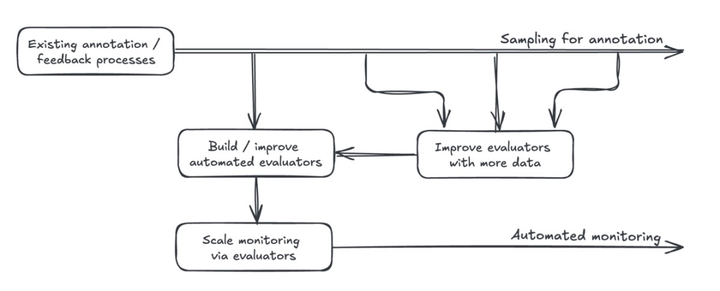
自动化评估工具本质上是人工标注与反馈流程的放大器。
虽然使用 AI 构建产品感觉很神奇,但仍然需要耗费大量精力。如果团队不应用科学的方法,实践评估驱动的开发,并监控系统的输出,那么购买或构建另一个评估工具将无法挽救产品。
原文链接:https://eugeneyan.com/writing/eval-process/
文章来自微信公众号 “ 机器之心 ”,作者 “ 张倩 ”

【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


