AI能看图,也能讲故事,但能理解“物体在哪”“怎么动”吗?
空间智能,正是大模型走向具身智能的关键拼图。
面对1000道多图推理题,开源大模型集体失守——准确率不到30%,甚至不如瞎猜!就连最强的OpenAI o3,也只答对了41%。
这一专为多图像空间智能设计的MMSI-Bench由上海人工智能实验室、香港中文大学、浙江大学、清华大学、上海交通大学、香港大学以及北京师范大学的研究者们共同完成。

MLLM在连接语言视觉、理解物理世界方面进展飞速,是通往具身AGI的关键。其中,空间智能(即理解物体位置、运动等空间关系的能力)至关重要,是自动驾驶、机器人导航与操作等应用的基础。
然而,当前评估MLLM空间智能普遍存在一些问题:
1、单图像局限
多数仅考察单图像内的简单关系。
2、低估真实世界复杂性
真实空间理解需跨多图像追踪、关联实体。
3、多图像覆盖不足
现有少数多图像基准对空间智能的覆盖既不全面也不深入。
4、模板化与合成数据
依赖模板或合成场景限制了问题的多样性与真实性。
因此,缺乏能检验真实多图像推理的基准,就无法可靠衡量和提升MLLM的空间认知。为此,MMSI-Bench的提出正是为了弥补这一评测空白。
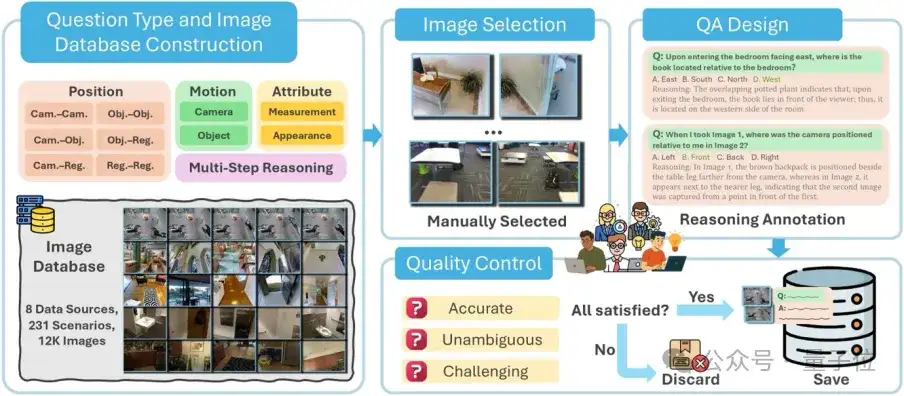
MMSI-Bench是一个用于评估MLLM多图像空间推理能力的VQA基准,设计过程中重点考虑了空间理解的关键要素和数据质量的可靠性。
MMSI-Bench采用完全以人为中心的设计。六位资深3D视觉研究员投入超300小时,从12万余张图像中精选并构建了1000个高质量问答对。
每个问题均极具挑战、答案无歧义,且必须整合多图像信息解答。问题配有精心设计的干扰项和详尽的步骤化标准推理过程,并经第二标注员严格审核,确保质量。

为系统评估多图像空间推理,MMSI-Bench围绕相机/智能体、物体、区域三个基本空间元素及其位置关系、属性、运动状态构建了全面任务分类。共定义10种基础空间推理任务和1种多步推理(MSR)类别:
除MSR外,其他类别问题均基于两张图像,专注核心的多图像整合能力。
为确保评估的全面性和真实性,MMSI-Bench图像全部源于真实的、多样化的场景数据集,包括ScanNet,Matterport3D(室内3D场景),nuScenes,Waymo(自动驾驶),AgiBot-World(机器人),DAVIS 2017(视频物体分割),Ego4D(第一人称视角视频)及DTU(局部场景重建)。这些丰富数据源使MMSI-Bench能构建覆盖广泛真实世界场景的问答对。
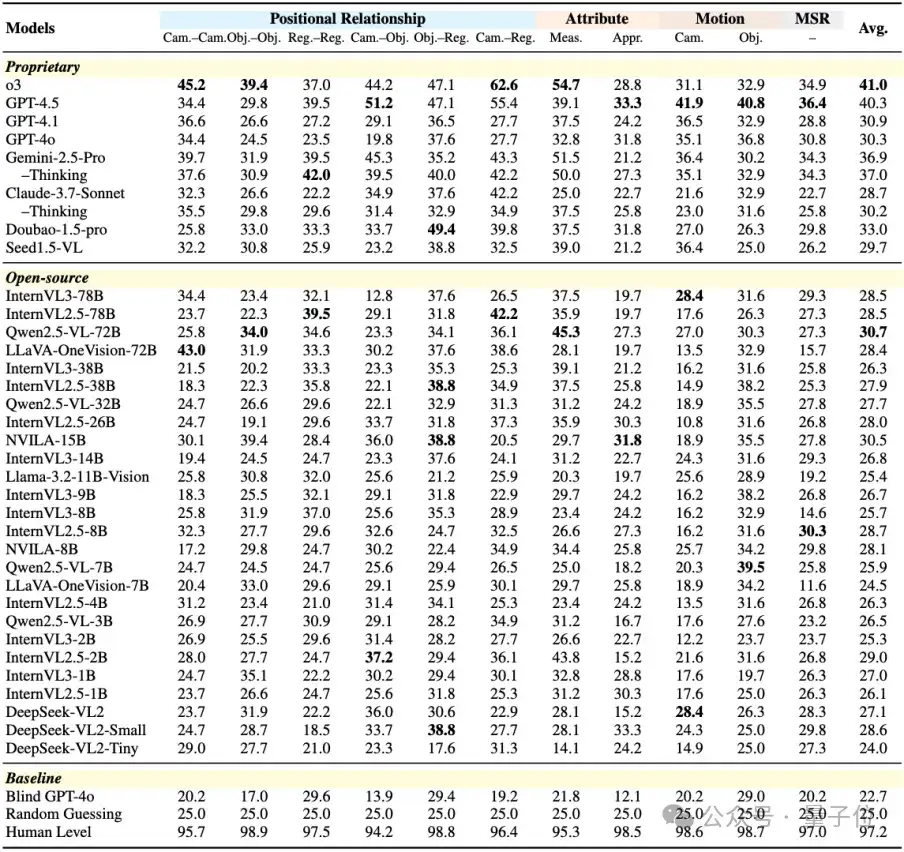
作者在MMSI-Bench上对34个广泛使用的MLLM(包括商业模型如o3,GPT-4.5,GPT-4o等,以及开源模型如Qwen2.5-VL,InternVL系列等)进行了全面评估。
主要发现包括:
1.MLLM在多图像空间推理上举步维艰
即便是最先进的MLLM也表现出显著局限。多数模型平均分仅略高于25%的随机猜测。表现最佳的商业模型OpenAI o3准确率仅41.0%,而人类高达97.2%,差距超56%,凸显了MMSI-Bench的挑战性。“思考模式”等策略提升有限,“盲眼GPT-4o”(无图像输入)准确率近乎随机,证明了任务对真实视觉空间推理的依赖。
2.先进开源模型仍落后于商业模型
表现最佳的开源模型Qwen2.5-VL-72B平均准确率为30.7%,明显落后于顶尖商业模型。
3.多步推理和相机运动理解是重灾区
多数模型在MSR任务上性能低于单步任务平均水平。尤其开源模型在相机运动任务上表现不佳,暗示MLLM理解自身运动的能力堪忧。
4.模型规模扩大增益有限
同系列模型增加参数带来的性能提升有限(如Qwen2.5-VL-72B仅比32B高3%)。这表明数据质量和多样性可能是当前提升复杂空间推理能力的主要瓶颈,而非模型规模。
5.提示工程效果有限
语言提示(如Zero-Shot CoT)和视觉提示(如PATS匹配)对性能提升甚微,甚至有负面影响,佐证了模型基础空间理解能力的缺失。
为探究MLLM在多图像空间推理上的瓶颈,作者对代表性模型(GPT-4o)的推理过程进行了细致的人工分析,归纳出四种主要错误类型:
这些错误分类清晰指出了当前MLLM在空间智能方面的具体短板。
MMSI-Bench每个问题均附带高质量的人类标注推理过程,基于此,作者开发了一套自动化的错误分析流程,以高效、规模化地诊断模型失败原因。
该流程利用强大语言模型(如GPT-4o)作为评估器,结合基准问题、图像、标准答案及MMSI-Bench提供的人类标注参考推理,判断待评估模型推理过程的正确性,并从上述四种错误类型中识别关键错误。
此自动化错误分析流程的价值:
通过人工洞察与自动化工具的结合,MMSI-Bench不仅衡量模型表现,更深入探究失败原因,为推动MLLM空间智能发展提供有力支持。
目前已有多个团队在打造面向多模态大模型(MLLM)的空间智能评测,而MMSI-Bench具备以下特点:
1.专注多图像空间智能:十个基础任务都基于两张图片,进阶多步推理任务会用到更多图片。
2.高质量:所有题目均由人工精心设计:从选图、出题,到干扰项设置与逐步推理标注,全流程把控。
3.贴近真实场景:图片来自自动驾驶、机器人操作、场景扫描等真实环境;题目关注真实场景的理解与推理。没有使用任何合成数据或者不贴合真实场景的问题。
4.评测全面且有挑战:研究者评测了 34 个模型(几乎涵盖所有受众广的闭源和开源模型),发现模型与人类表现仍有巨大差距,多数开源模型仅相当于随机猜测。这可能是目前模型-人类差距最大的基准评测。
5.完整推理过程:每个样本都附带人类标注的推理流程,可解释答案正确性,也便于自动化定位模型错误。
MMSI-Bench作为专为多图像空间智能设计的挑战性综合基准,通过对34个顶尖MLLM的评估,清晰揭示了其与人类水平的巨大鸿沟。希望MMSI-Bench能成为社区宝贵资源,推动开发空间感知更强、更鲁棒的多模态AI系统,加速通往真正理解并与物理世界交互的AGI。
项目主页: https://runsenxu.com/projects/MMSI_Bench
ArXiv论文: https://arxiv.org/abs/2505.23764
Hugging Face数据集:https://huggingface.co/datasets/RunsenXu/MMSI-Bench
GitHub代码库: https://github.com/OpenRobotLab/MMSI-Bench
文章来自于微信公众号“量子位”。

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/


