过去几年,随着基于人类偏好的强化学习(Reinforcement Learning from Human Feedback,RLHF)的兴起,强化学习(Reinforcement Learning,RL)已成为大语言模型(Large Language Model,LLM)后训练阶段的关键技术。RL 不仅显著提升了模型的对齐能力,也拓展了其在推理增强、智能体交互等场景下的应用边界。围绕这一核心范式,研究社区不断演化出多种优化策略和算法变体,如 Agentic RL、RLAIF、GRPO、REINFORCE++ 等。这些新兴范式虽然形式各异,但底层需求高度一致:几乎都涉及多模块协同(Actor、Critic、Reward、Ref)与多阶段流程(生成、推理、训练)的高效调度。这也对训练框架提出了更高的要求:不仅要支持大规模模型的高效训练,还需具备良好的可扩展性与开发友好性。因此,一套真正高效、可扩展且用户友好的 RL 系统框架,成为业界刚需。
近日,淘天集团携手爱橙科技正式开源了全新一代强化学习训练框架 ROLL(Reinforcement Learning Optimization for Large-scale Learning)。ROLL 以用户体验为核心设计理念,专为「高效・可扩展・易用」而打造,彻底打通从小模型到 600B+ 超大模型的 RL 训练落地路径。
ROLL 在诸如人类偏好对齐、复杂推理和多轮自主交互场景等关键领域显著提升了大语言模型的性能,同时具备超高的训练效率,目前 ROLL 已成功应用在多个淘天集团内部业务场景, 为业务创新提供了强大的技术支持。

总体而言,ROLL 具有以下关键特性:
目前,该项目已经在 GitHub 上收获了 1000+ star。
ROLL 是一款面向用户友好设计的强化学习框架。具体来说,ROLL 从一开始就考虑了三类用户诉求,即:技术先驱者、产品开发者和算法研究者。
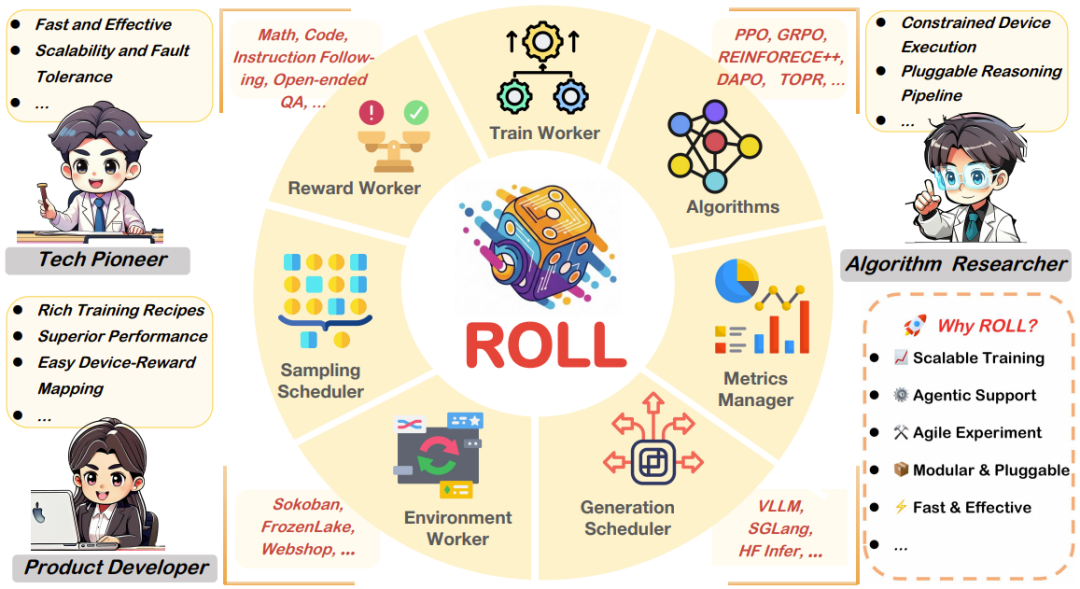
ROLL 针对三大用户群体设计
那么,ROLL 是如何做到的呢?具体来说以下多项创新:
下图展示了 ROLL 的整体架构。ROLL 接收的输入是用户定义的强化学习数据流及其相关配置。基于这些输入,分布式执行器和调度器可协调管理各类工作节点和调度节点。 而 AutoDeviceMapping 模块则负责管理已分配资源池中的计算资源,并高效地将工作节点和调度节点绑定到其分配的资源上。
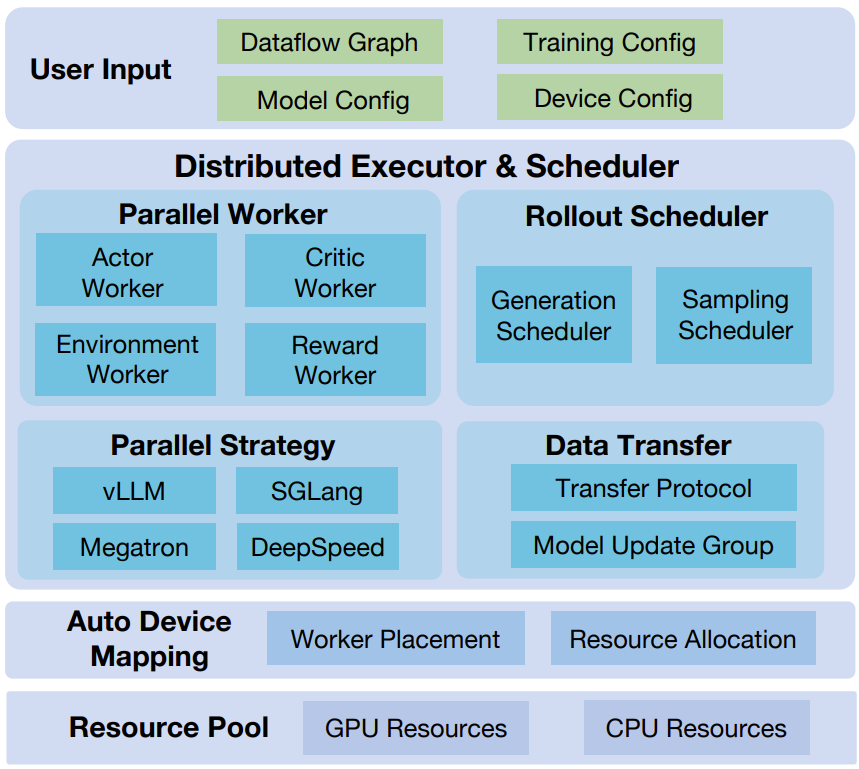
ROLL 的架构,由用户输入层、分布式执行器和调度器、Auto Device Mapping 模块以及资源池组成。
而在运行时,ROLL 首先会根据提供的设备配置,分配由 GPU 和 CPU 资源组成的资源池。在 RL 数据流的指导下,系统会创建一个 Rollout 调度器和多个并行工作器。其中,Rollout 调度器负责管理生成阶段中每个提示词样本请求的生命周期。
然后,根据训练和模型配置,ROLL 会实例化并行策略,以决定每个并行工作器的并行策略和执行后端。一旦并行工作器建立完成,ROLL 将依据用户指定的设备映射配置,调用 AutoDeviceMapping 模块,从资源池中为各个并行工作器分配相应的计算资源。如下图所示。
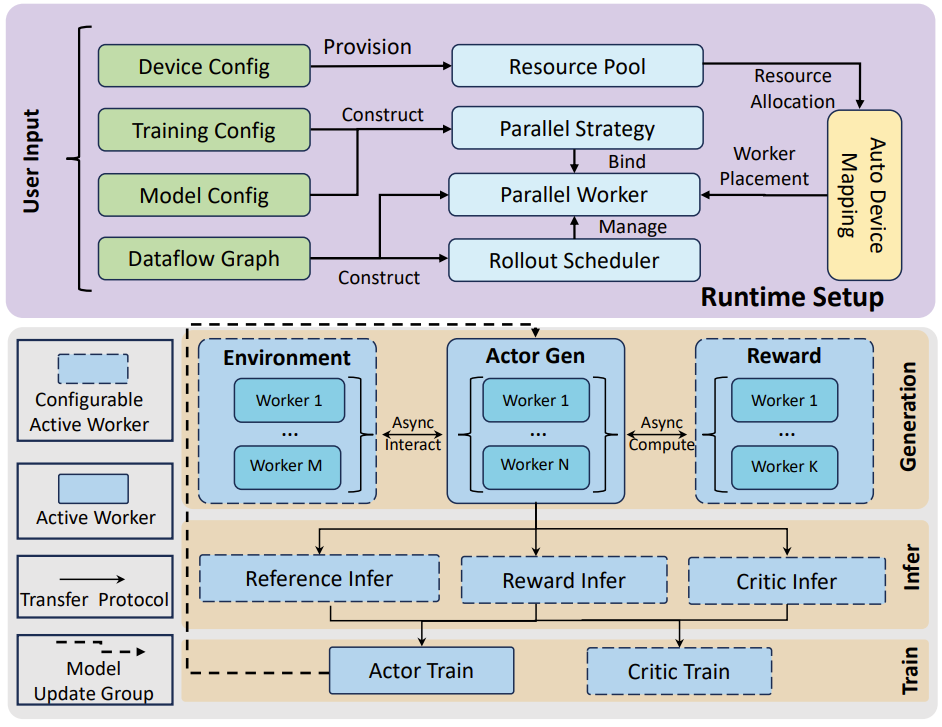
ROLL 的运行时设置和训练工作流程。
接下来,进入训练迭代。在生成阶段,首先将一批样本送入 Rollout 调度器以生成响应。在此过程中,Actor 模型可能会与环境工作器进行交互,以实现智能体强化学习任务中的多轮环境互动。同时,系统也会调用奖励工作器来计算奖励信号,从而支持高级采样技术(例如动态采样)以提升采样效率。
在接下来的推理阶段,会执行 Critic、Reward 和 Ref 模型(前提是这些模块已在 RL 数据流图中启用)的前向传播。随后,迁移协议会对生成阶段输出的响应进行分片,并将其分发给各个活跃的并行工作器。
在训练阶段,Critic 和 Actor 模型利会用已准备好的奖励信号更新各自的参数。此外,在下一轮训练迭代中,Actor 模型还会通过 ModelUpdateGroup 与生成阶段同步模型参数,确保训练与生成过程的一致性。
另外,ROLL 也支持 wandb、swanlab、TensorBoard 等实验可视化方案。更多技术细节请访问原论文。
在 Qwen2.5-7B-base 与 Qwen3-30B-A3B-base 等模型上,ROLL 取得了显著的跨领域多任务性能提升。例如,在 RLVR pipeline 训练下,Qwen2.5-7B-Base 的整体准确率从 0.18 提升至 0.52(2.89 倍),Qwen3-30B-A3B-Base 准确率从 0.27 提升至 0.62(2.30 倍),这两个模型在 ROLL 的支持下均展现了稳定且一致的准确率提升,且未发生模型崩溃等异常现象,展现了 ROLL 极佳的稳健性和实用性。
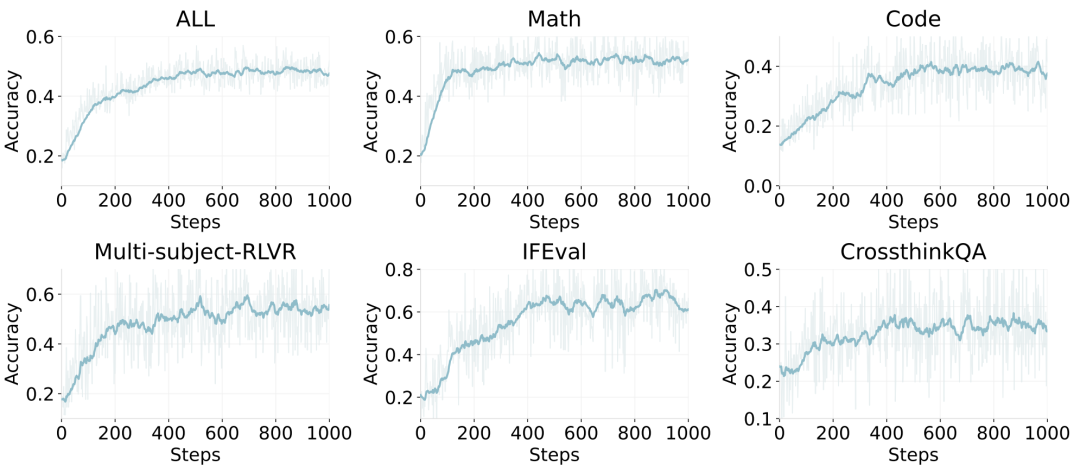
Qwen2.5-7B-base 在不同领域上的准确度表现。
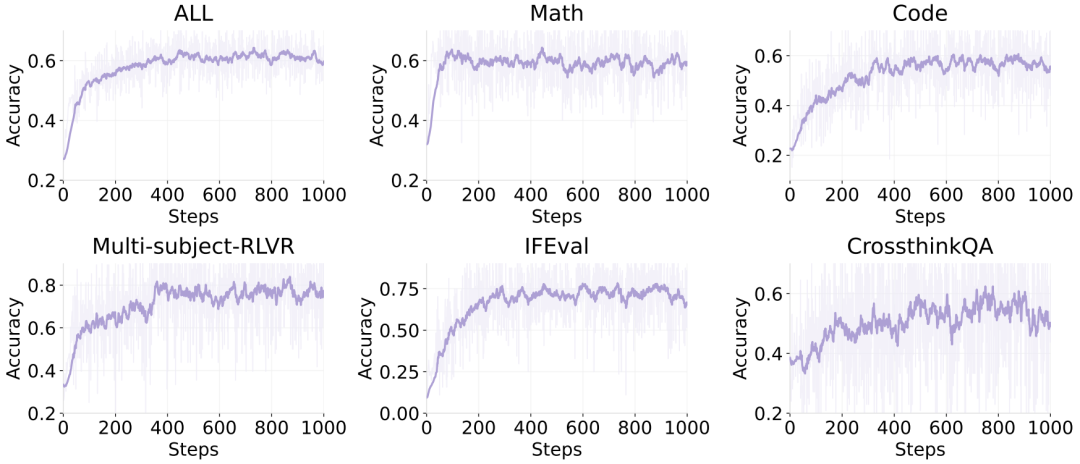
Qwen3-30B-A3B-base 在不同领域上的准确度表现。
除了标准 RL 流程,ROLL 在智能体交互场景中同样展现了强大的稳健性。研发团队在三个典型环境下对 ROLL 的泛化性与适应性进行了实证验证:

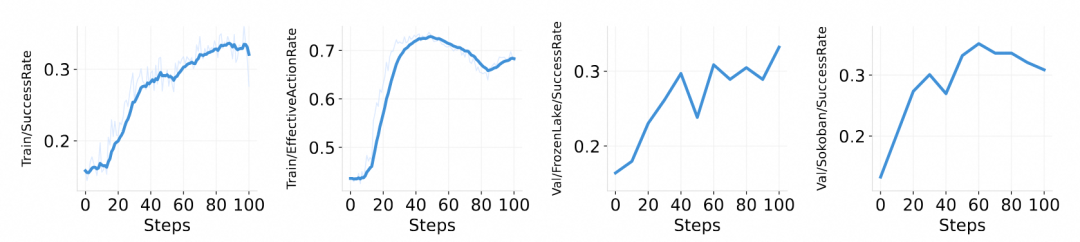
在 SimpleSokoban 环境训练的性能变化趋势,SuccessRate 表示达到目标的成功率 EffectiveActionRate 表示执行有效动作的比例。

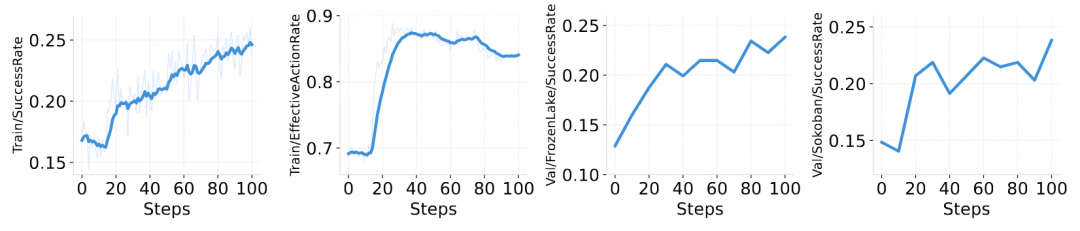
在 FrozenLake 环境训练的性能变化趋势。
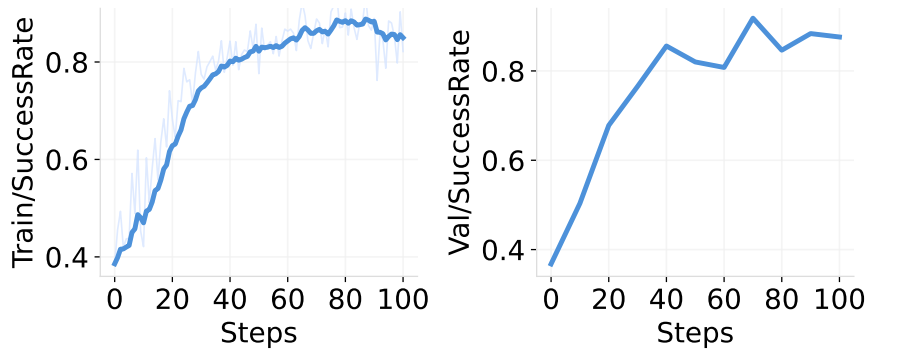
在 WebShop 环境上的准确度趋势。
ROLL 已在 GitHub 上线,并在短时间内收获大量 star。项目仍在持续迭代,未来将支持 Qwen2.5 VL Agentic RL、一步式异步 pipeline、FSDP2、DeepSeekV3 等新特性,欢迎关注并参与共建。
开源精神是推动技术发展的核心引擎,ROLL 研发团队期待更多优质人才加入。这里既有技术攻坚的硬核挑战,也有共创未来的无限可能。
热招岗位:
顺带一提,淘天集团第四届技术节【硬核少年技术节 4.0】将于 2025 年 6 月 30-7 月 4 日在北京和杭州两地隆重举办。本届技术节持续一周,包含技术市集、博见社、Openday、AI 狼人杀、AI Hackathon 比赛等各类丰富多彩的 AI 展示场、AI 交流场、AI 开放场、AI 比赛场。
7 月 2 日下午 14:00,此次技术节的重磅 AI 交流场 ——【博见社】,将进行「多模态智能」方向的专场主题分享和「多模态智能与 AI Agent」的圆桌交流,嘉宾包括中科院自动化所研究员刘静、哈尔滨工业大学计算机学院长聘教授左旺孟、南京大学计算机学院教授王利民、清华大学计算机系副教授刘知远、中国人民大学准聘副教授李崇轩等学者。欢迎大家预约直播观看。
文章来自于微信公众号“机器之心”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales


