每当需要处理复杂领域中高度不确定性或缺乏历史数据的问题时,纯粹的科学证据不足、存在矛盾或过于复杂,通常我们就需要依赖专家们的集体智慧来形成共识,指导实践。德尔菲法(Delphi method)是半个多世纪以来最常用的一种专家共识方法。它的特点是匿名输入、多轮反馈和统计汇总,旨在减少权威偏见,让观点得以修正和趋同,最早由兰德公司在1950年代为美国空军开发,用于预测苏联若发生核打击的可能情景,后来广泛应用于技术评估、医疗、企业战略等需要处理高度不确定性或缺乏历史数据的复杂领域。

但尽管德尔菲法非常经典,但它也存在一些问题
面对这种困境,研究者们设计了一套全新的玩法,叫“Human-AI Hybrid Delphi Model”(人机混合德尔菲模型, 简称HAH-Delphi),它的核心就是“人机协同”。这个框架由三个关键部分组成,分工明确,就像一个高效的作战小队。

那么,AI在这里到底算什么角色?这一点特别有意思,AI的身份是双重的。一方面,它是协调人的强大工具,在研究前期帮助协调人梳理文献、设计问卷,干的是“体力活”;另一方面,在正式讨论中,它又是一名特殊的、独立的“专家”,会像人类专家一样对问题给出自己的评分和理由,但它的特殊之处在于,它的所有观点都严格来自文献数据,不带任何个人经验和偏见。
论文明确强调,AI的角色是 “增强而非替代” 人类专家。AI擅长提供基于证据的推理,但它无法复制人类专家独有的、基于真实世界经验的“经验性”和“实用性”判断。例如,AI可能知道一种疗法有效,但人类专家会知道在特定病人身上、考虑到其生活环境和经济状况时,这种疗法是否可行。因此,AI是一个没有偏见但也没有实践智慧的“博学同事”
为了验证这个创新模型的有效性,并确保它不只是一个理论框架,研究者们设计了一个包含三个环环相扣阶段的严谨流程,从回顾性验证、前瞻性比较到最终的实际应用,系统性地测试了其可行性与价值 。
这套模型之所以厉害,主要靠的是两个方法论上的创新,它们像两把锋利的手术刀,精准地剖析并保留了专家智慧的精髓。
这个模型之所以能用6个人的小组做出判断,关键就在于它不追求统计上的代表性,而是追求“认知上的完备性”。它的重点从“有多少人同意”转向了“专家们为什么同意,以及在何种条件下同意”。
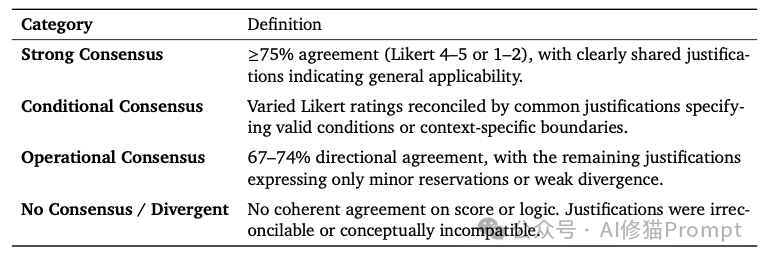
传统的德尔菲法依赖于量化的百分比来决定共识,而HAH-Delphi则采用了一种量化与质化相结合的、更加注重深层逻辑的标准。最终的共识是建立在对专家们深层逻辑的理解和整合之上的,而不是对评分进行简单的算术平均或统计。这使得结论更加细致、实用,并且能够保留传统方法中经常被“平均掉”的宝贵情境智慧。
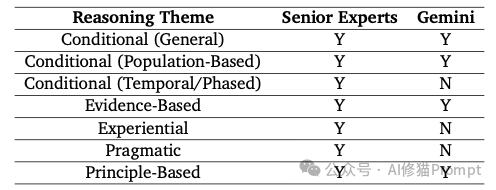
为了解决传统方法需要大量专家的问题,研究者引入了“主题饱和度评估”这个概念。他们预先定义了专家在思考问题时可能用到的七种推理模式,这个设计真的非常巧妙。
在讨论过程中,协调人会持续追踪这些推理类型是否都已出现,在对资深专家的访谈中,通常在第5或第6个人之后,就几乎不会再出现全新的观点或推理类型了,即达到了“主题饱和”。这个信号说明:虽然专家人不多,但观点已经足够全面了,没必要再增加人手了。证明小组虽小,但在认知层面已经足够完备。
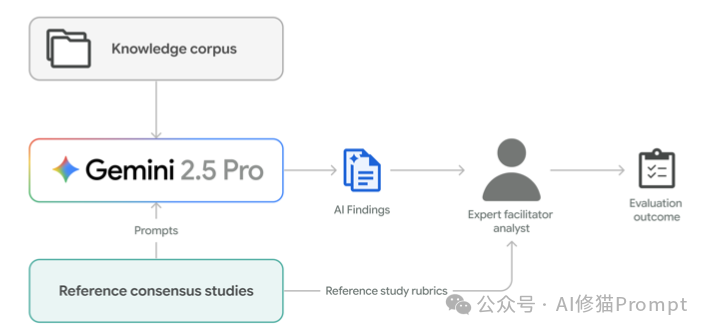
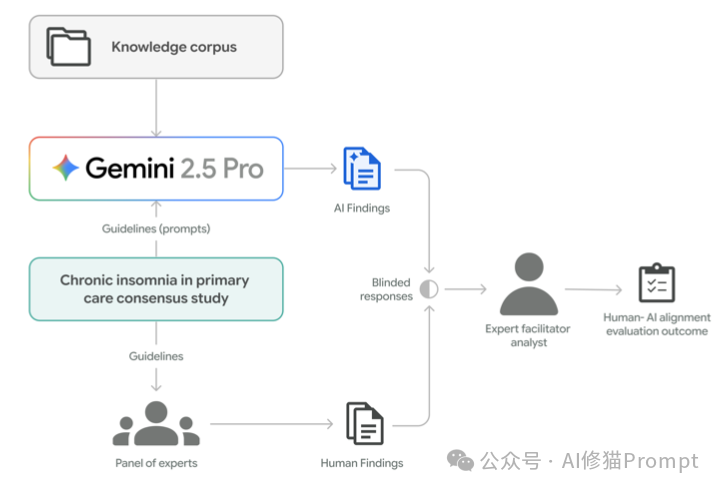
让AI参与讨论,一个关键问题就是如何确保它和人类专家在“一个频道”上对话。HAH-Delphi模型通过一套清晰的评估流程来管理人机“对齐”,这里的“对齐(Alignment)”不是强求观点一致,而是评估AI的回答与人类共识的契合度,这个过程由人类协调人来裁决。
这个评估之所以能实现,得益于前期严格的设定:AI只能在协调人预先圈定的、可信的公开知识库里学习和回答,这从源头上保证了AI不会“自由发挥”,也为后续的对齐评估提供了坚实的基础。
最后一步是将上述所有分析结果,综合提炼成一份结构化的、丰富的“指导原则”(Guiding Principles)。以附录中的力量与混合有氧/力量训练指导原则为例

HAH-Delphi模型的最终产出是一套结构化、情境化、诚实反映不确定性、并极具实践指导价值的原则框架,而非简单地罗列出所有“强共识”的结论或一份简单的“是/否”清单
顶尖专家的核心价值不在于他们作为一个群体能达成多少百分比的共识,而在于他们每个人头脑中那套无法被文献复刻的、基于经验的、带条件的推理模型
未来,真正的专家优势将是“情境智慧”(Contextual Intelligence)。AI可以掌握所有公开的“知识”(Knowledge),但无法拥有人类专家通过长期实践内化而成的“智慧”(Wisdom)。这篇论文的模式,通过系统性地提取和构建这种智慧,实际上是在为专家价值进行“资产化”。对于任何依赖高端人才的组织而言,这意味着需要建立新的机制来识别、萃取和放大这种顶尖的、隐性的个人智慧,而不是仅仅将他们作为决策流程中的一个投票环节。论文最后甚至指出,这些人类专家是“下一代AI推理的必要架构师”。
传统共识方法致力于产出一个统一、普适的“最佳实践”或“标准答案”。HAH-Delphi模型则承认,在复杂世界中,“唯一答案”往往是一种有害的过度简化。
未来的知识产品(无论是临床指南、企业战略)将不再是一本指令手册,而更像是一幅详尽的“决策地形图”。这篇论文的“四级共识框架”就是这张地图的图例。它清晰地标出了哪些是平坦大道(强共识)、哪些是需要特定装备才能通过的山路(条件共识),以及哪些是充满争议的未知领域(分歧)。这种范式转移对于任何决策者都至关重要:他们需要的不是一个僵化的指令,而是一个能帮助他们根据自身具体情况(情境)做出最优判断的、充满智慧的导航系统。
HAH-Delphi模型提供了一个 “敏捷治理”(Agile Governance) 的实现蓝图。通过小规模专家组、AI辅助和高效的单轮流程,它能够在极短的时间内,针对一个复杂问题形成深入、可靠的指导原则。想象一下,一个企业可以在一个季度内,利用这个模型为一项新兴技术(如AIGC应用)快速制定出兼具原则性和灵活性的内部使用指南,而不是花费一年时间开无数次大会。这种将顶级智慧快速转化为组织行动力的能力,将是未来一种核心的战略优势。
在许多关于AI的讨论中,人们担心的是中低技能岗位被取代。而这篇论文则有力地证明,在高端人机协作中,一个拥有极高专业素养和综合能力的“人类协调人”(Human Facilitator)是不可或缺的、价值倍增的关键角色
这个协调人绝非简单的会议主持 。他/她必须是领域专家、方法论专家和“翻译家”,能够理解AI的输出、解读专家字里行间的深意、弥合评分与理由的偏差,并最终将所有碎片化的信息综合成一个连贯的智慧框架 。在未来的人机团队中,这种能够驾驭AI、赋能专家、整合智慧的“枢纽型人才”将变得极其宝贵。对于个人职业发展和组织人才战略而言,这意味着需要大力培养这种跨领域的、具备极强综合与思辨能力的“人机协作指挥官”
文章来自于微信公众号“AI修猫Prompt”。
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


