随着AIGC技术的进步,连环画与故事绘本生成(故事可视化)逐渐引发学界与业界的广泛关注,成为电影生成叙事性的基础。
故事可视化旨在用一段文字或照片生成一组连续的图片。
但生成的质量如何呢?我们需要系统性关注哪些指标呢?
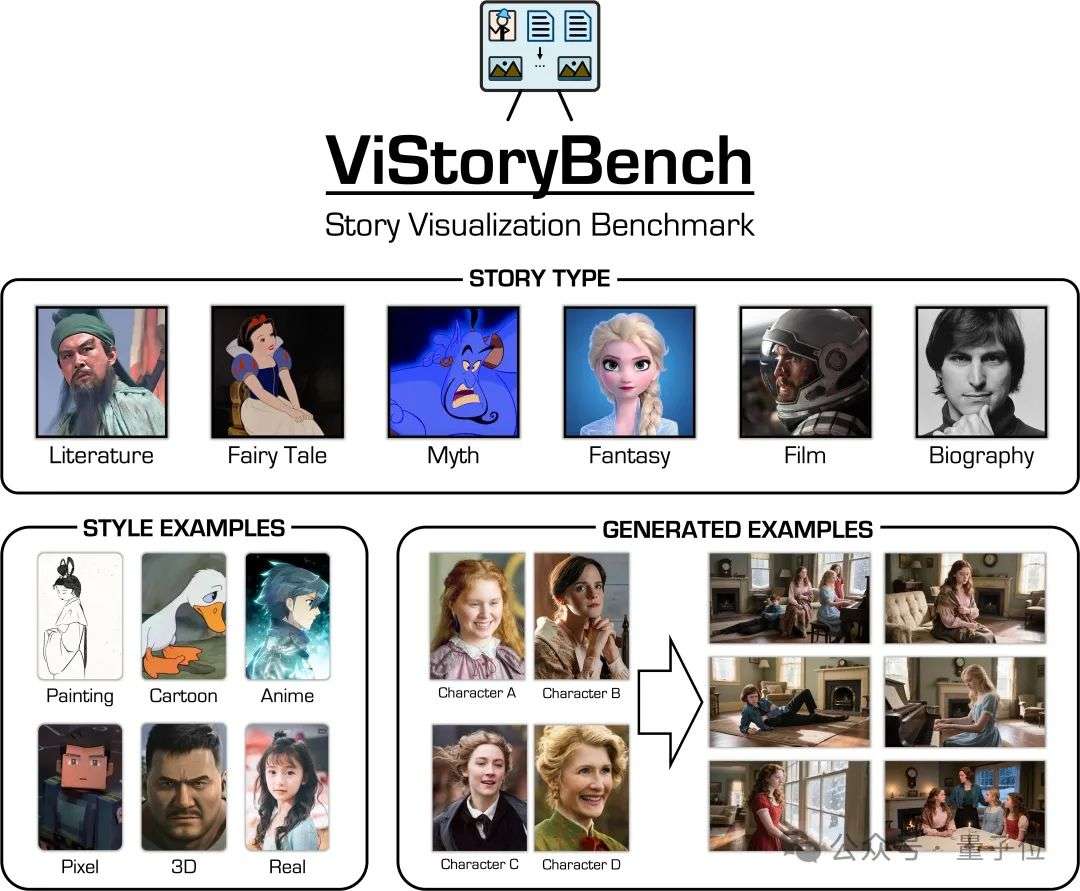
现在,一套综合评估基准来了!阶跃星辰携手上科大、西湖大学提出ViStoryBench可视化评估框架,通过多维度、多层次的测试标准,客观衡量故事可视化模型在真实应用场景中的表现。
以下视频来源于
AIGC Research

故事可视化技术的核心挑战在于确保角色形象的一致性,同时构建富有细节的复杂叙事场景和世界观。
当前,扩散模型和自回归生成技术的突破显著提升了长篇幅故事的可视化能力,但现有的评估体系仍存在明显不足——指标单一、维度局限,难以全面反映生成质量。
团队注意到现有评估方法在题材多样性、视觉风格谱系等关键维度上有所缺失。
而ViStoryBench的提出正是为了建立更科学的评估框架。

该基准不仅关注技术实现,更重视艺术表达与叙事逻辑的有机统一,为行业发展提供可靠的评估工具。
下面具体看看他们是怎么做的。
ViStoryBench作为一套综合评估体系,旨在全面解决故事可视化领域评估标准多样化和多维化的问题。具体如下:
数据集创建
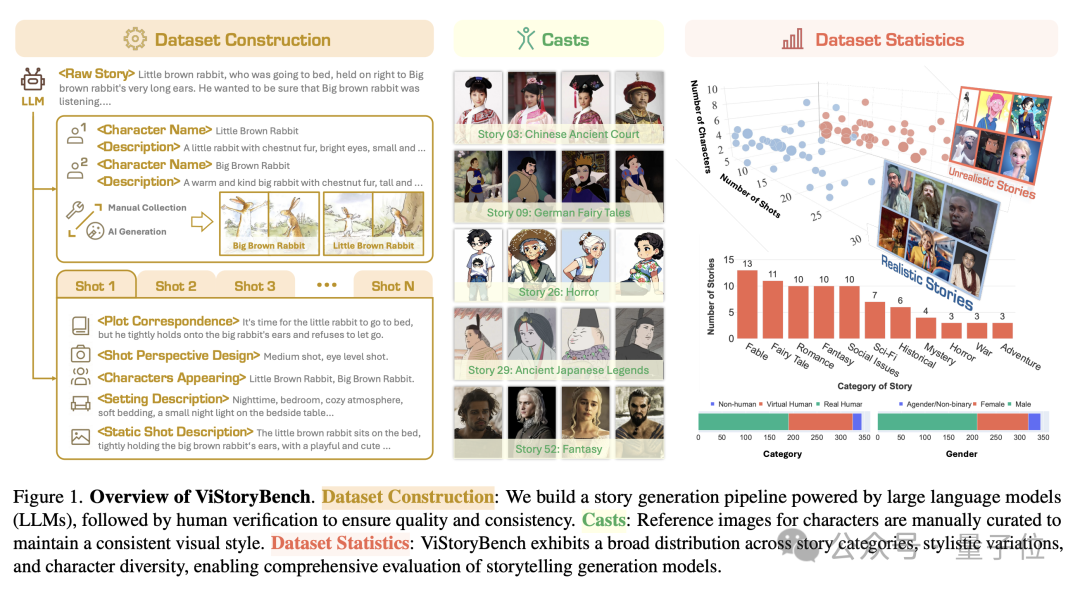
团队精心构建了一个多元化数据集,同时包含中文和英文内容,全面覆盖不同类型的故事题材和艺术表现形式。
该数据集由80个故事单元组成,涉及53种故事类别,包含344个独立角色,在叙事框架和视觉要素之间实现了良好平衡。
数据集设计包含单一主角和多角色互动的故事情境,每个故事涉及的角色数量在2至10人之间,专门用于检验模型在多角色形象连贯性方面的表现。
同时,数据集还纳入了情节复杂度高、世界观设定细致的叙事内容,每个场景单元均包含主观叙事(角色与环境的关系描写,类似小说手法)、客观叙述(角色间或角色与环境的具体互动,类似剧本格式)、场景布置(类似舞台设计)、镜头构图(类似摄影指导)以及角色出场信息,以此全面测试模型生成精准视觉内容的能力。
采用人工筛选与AI辅助相结合的方式,从影视剧本、文学著作、民间传说、小说及绘本等渠道精选80个故事样本。
针对篇幅过长的原始素材,团队运用大型语言模型(如Step-1V)进行内容提炼,确保每个故事样本保持数百单词的适宜长度。随后将这些故事素材转化为标准化的剧本格式,同时补充详细的角色设定和分镜脚本。
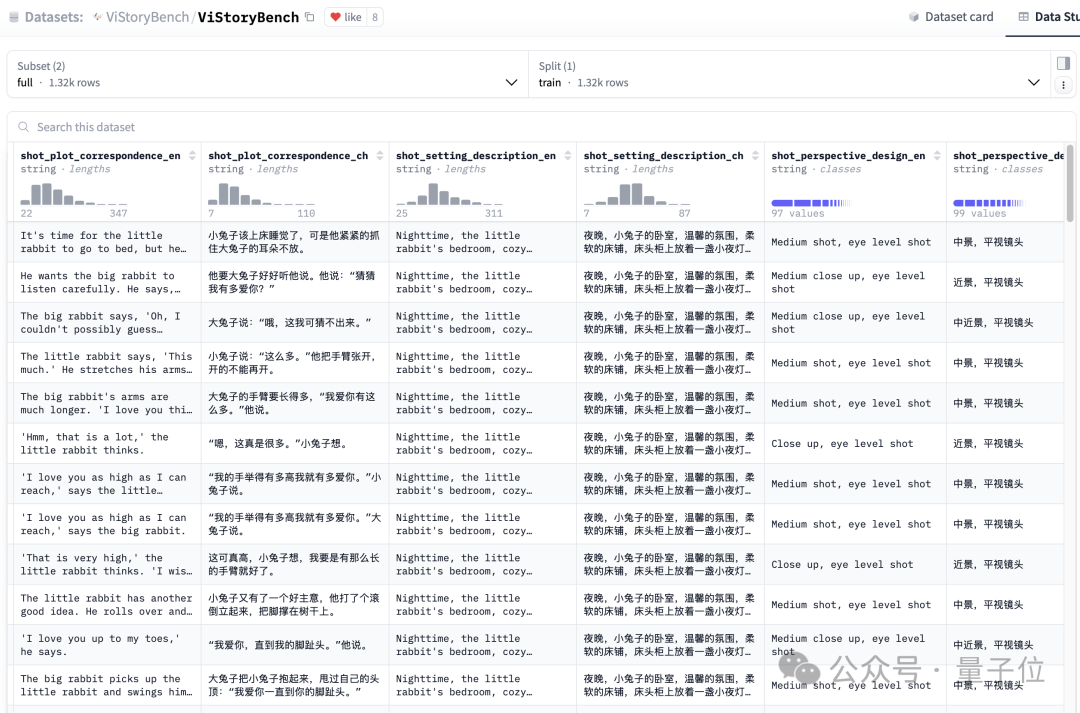
通过人工采集与AI生成相结合的方式,严格筛选与角色设定相匹配的视觉参考图像,保证同一故事单元内所有角色形象的美术风格协调统一。
其中部分角色参考图像采用SDXL模型生成。最终共整理出344个角色档案及509张参考图像。

评估指标

团队建立了一套多维度的综合性评估框架,包含角色与风格相似性分析、细粒度提示对齐、美学质量评估及复制粘贴行为检测等核心指标,用以全面衡量主流方法在生成连贯图像序列方面的表现。具体评估维度如下:
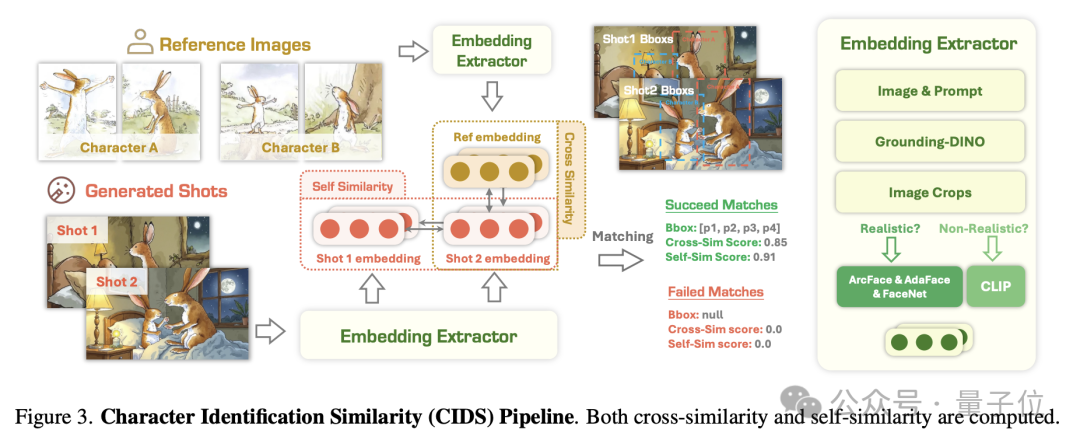
简单来说,该系统就像一个“火眼金睛”的安检员。它先用一个模(GroundingDINO)在生成的图片中准确地“框出”所有角色,然后再用另一个人脸识别模型(ArcFace)来判断,这个被框出的角色到底是不是我们参考图片里的那个人,并给出一个相似度分数。
角色相似性从两个维度进行评估:
1.角色跨相似性:生成图像与参考图像之间的角色相似性、匹配度。
2.角色自相似性:生成图像序列之间的角色形象的一致性。
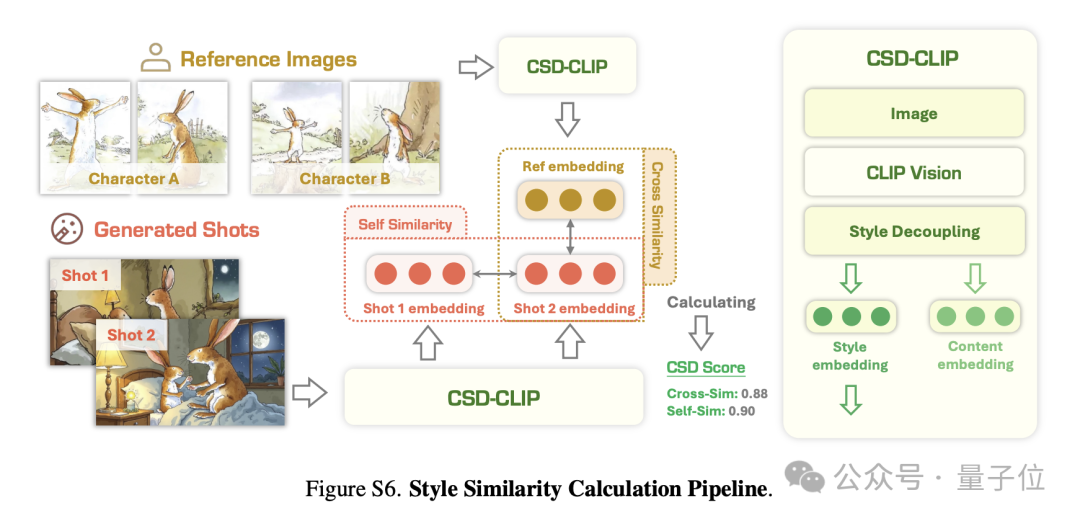
基于CSD杰出的风格特征解耦能力,风格相似性指标从两个层面进行量化:
1.风格跨相似性:生成图像与参考图像之间的艺术风格相似度、契合度。
2.风格自相似性:生成图像序列间的风格连贯性。

基于GPT-4.1的强大理解能力,评估生成图像与对应的提示中提供的剧本描述的一致性,主要对以下要素进行细粒度匹配验证:
1.场景设定的吻合度
2.镜头设计的契合度
3.角色动作/表情的准确呈现
4.多角色互动的合理表达
5.角色数量的准确性

团队还特别设计了登场角色数量匹配度(OCCM)指标,以统计了每个生成图像中登场角色数量的准确性,包括角色冗余与遗漏,角色数量的偏差直接影响OCCM的分值。
考虑到登场角色是由文本提示进行指定的,因此团队将其作为细粒度提示一致性下的一个衍生子类。
采用Aesthetic Predictor V2.5和Inception V3双模型架构,从三个维度进行评判:
1.美学质量:图像的艺术表现力
2.生成质量:生成图像的完成度
3.多样性:创意的丰富程度
同时专门配备了复制粘贴检测机制,来检查模型是否过度参考了角色参考图像(对参考图像的过度依赖)
团队对超过20种技术方案(包含18种主要方法及其变体)进行了系统性评测,覆盖开源方法(涉及故事图像与视频生成领域)、商业产品以及多模态大语言模型三大类别。
针对不同技术特性,团队设计了专门的数据适配方案,例如处理仅支持单角色生成的算法、优化长文本输入的兼容性等。
评测在完整版(full)和精简版(lite)两个数据集版本上进行,精简版数据集包含20个故事样本,涵盖36个动画角色、41个真实人物以及4个非人类实体。
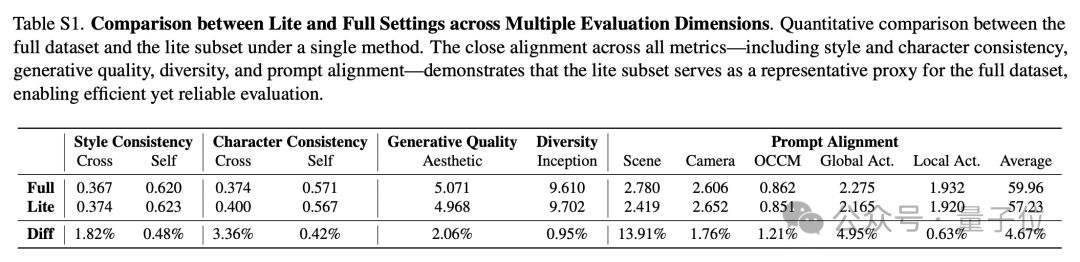
1.图像生成方法:评估了StoryDiffusion、Story-Adapter、StoryGen、UNO、TheaterGen和SEED-Story等多种图像生成算法。针对不同算法特性,采用不同输入配置,比如分别测试了纯文本输入、单图像参考输入以及多图像联合输入等配置方案。
2.视频生成方法:评估了Vlogger、MovieAgent、Anim-Director和MM-StoryAgent等多种视频生成算法。为确保评估标准统一,采用视频关键帧提取评估策略,或在特定场景下仅执行文本到图像的生成环节。
重点测试了GPT-4o和Gemini-2.0等先进模型。这些模型凭借强大的跨模态理解与生成能力,在故事可视化任务中展现出独特优势。
通过标准化预处理流程(包括尺寸调整、色彩空间转换等)将角色参考图像直接作为视觉条件输入,有效保证生成角色与设定外观的一致性。
利用模型的上下文记忆能力,在单次会话中连续生成同一故事的多组分镜图像,实现跨分镜的内容连贯性。
涵盖白日梦、豆包、讯飞绘影、神笔马良、Morph Studio、MOKI等商业产品。
针对部分缺乏开放接口的平台,组织全职专业标注团队在企业内部环境完成图像生成与采集任务。
所有商业产品的测试工作均统一在2025年5月1日至7日期间完成。


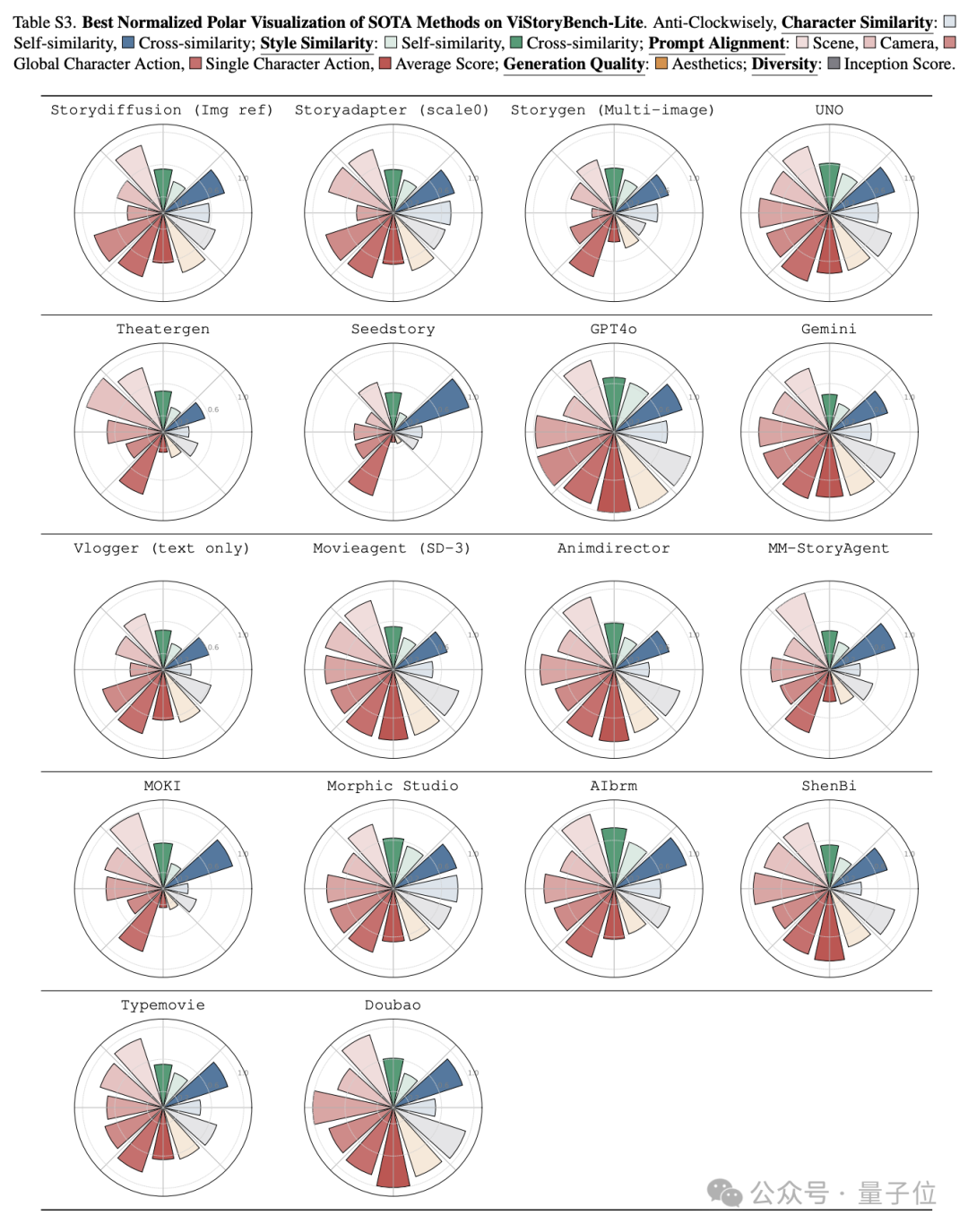
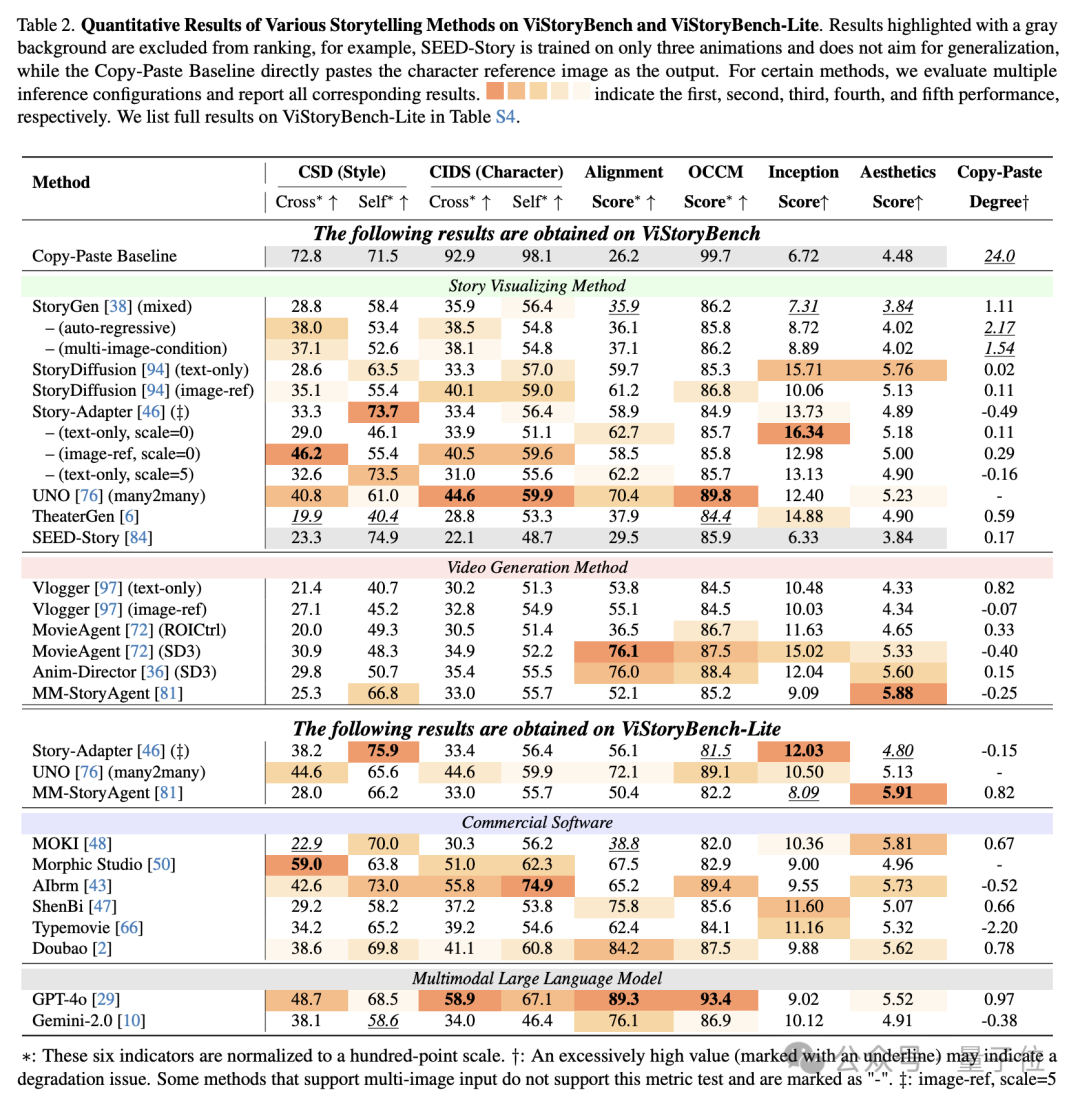
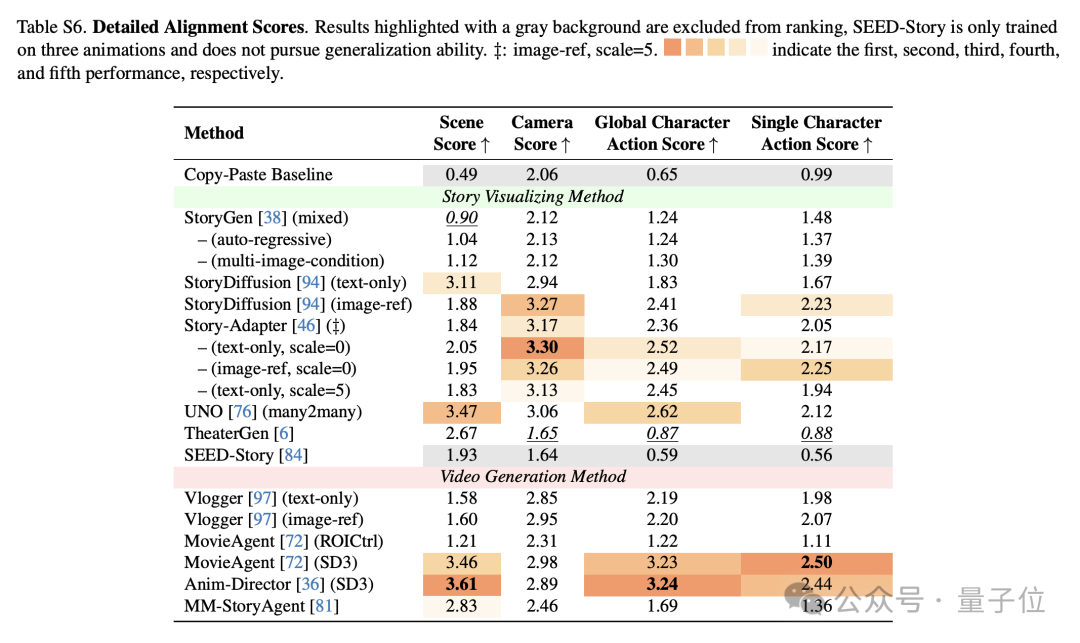

图表展示了不同方法在ViStoryBench和ViStoryBench-Lite上的自动化测试结果,团队观察到若干具有启发性的现象。
1.综合指标的必要性:测试结果表明,单一评估指标存在明显局限性,这一点在Copy-Paste Baseline的表现中尤为突出:该模型虽然在IS分数和美学评分上取得优异成绩,但其提示一致性Alignment Score却显著偏低,反映出仅追求视觉质量而忽视叙事逻辑的技术缺陷。
2.商业模型的优势与局限:商业模型展现出差异化特征,Doubao和GPT-4o凭借强大的语言理解能力在提示一致性(Alignment Score)和角色数量匹配(OCCM)指标上表现突出,而AIbrm等专用工具虽然在角色特征还原方面更为精准,却因文本指令解析能力的不足而影响整体评分。这一现象在用户研究中得到了印证:在满分为4分的主观评估中,豆包在“角色一致性”上以3.63分的高分领先,展现了其强大的角色锁定能力;而GPT-4o则在“主观美学”上以3.28分夺冠,其生成画面的艺术表现力更受用户青睐。ViStoryBench清晰地量化了不同顶尖模型间的“能力偏科”现象。这一现象揭示了不同技术路线的优劣势。
3.自动化指标能快速定位缺陷:从技术演进的角度看,较早期的StoryGen在图像多样性和质量上表现欠佳,而如今引入扩散模型的后续方法则显著改善了这一问题。值得注意的是,IS分数与美学评分的对比分析直观展示了模型在新颖性和视觉吸引力之间的平衡难题。
4.多模态输入的挑战:多模态处理方面,测试数据揭示了有趣的对比:部分方法在单图输入时往往表现出对参考图像的过度依赖(表现为较高的Copy-Paste Degree),而在多图输入时则展现出更好的综合性能。同时,部分商业工具由于架构限制无法支持多图输入,导致关键能力缺失。
5.评估体系的有效性得到验证:自动化指标与人工评价呈现高度相关性,特别是在CIDS与Character Consistency、Style Similarity与环境一致性等维度上。Story-Adapter在文本+图像双模态输入下的评分一致性优势尤为明显。
6.数据偏差与模型脆弱性:测试还暴露出现有技术的若干短板,包括对非人角色的生成能力普遍较弱、长文本输入时性能显著下降等问题,这反映出训练数据多样性和上下文建模能力仍有提升空间。
这些发现为故事可视化技术的优化方向提供了重要参考,凸显了建立多维度评估体系的必要性。
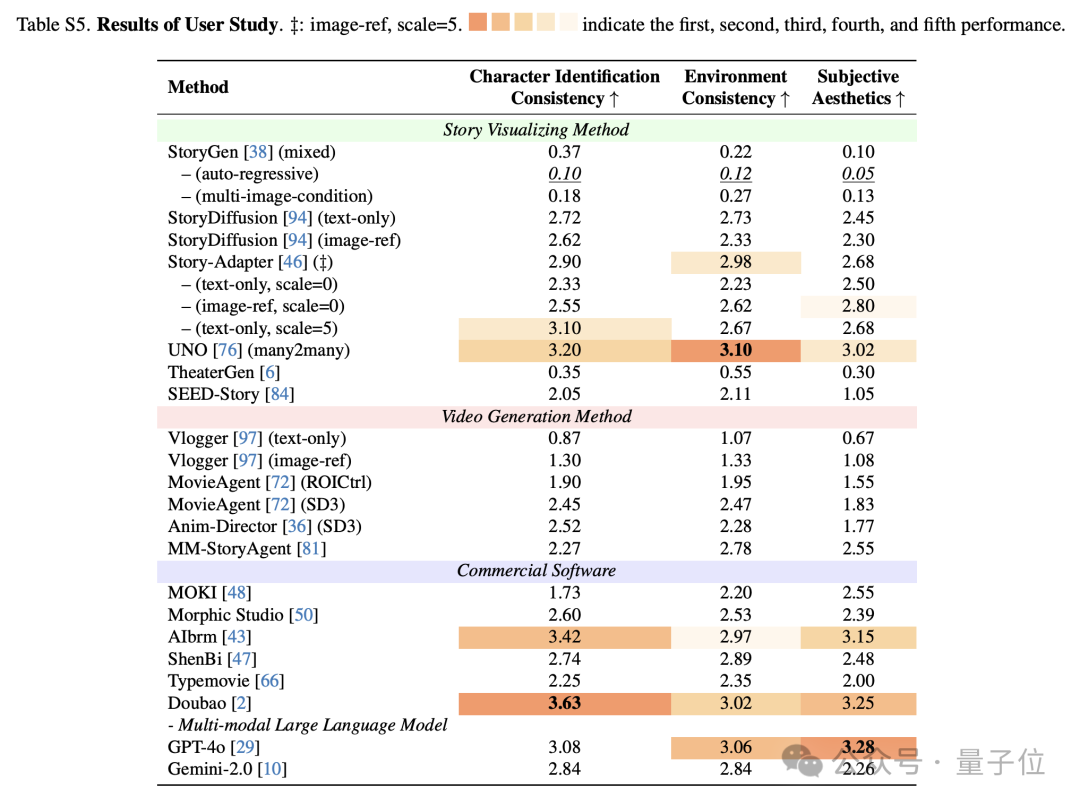
用户研究从角色一致性、环境一致性以及主观美学质量三个维度对生成图像进行了评估。研究发现,UNO模型在三个评估维度上都获得了较高的用户评分,而Doubao则在提示文本与生成内容的匹配度方面展现出明显优势。
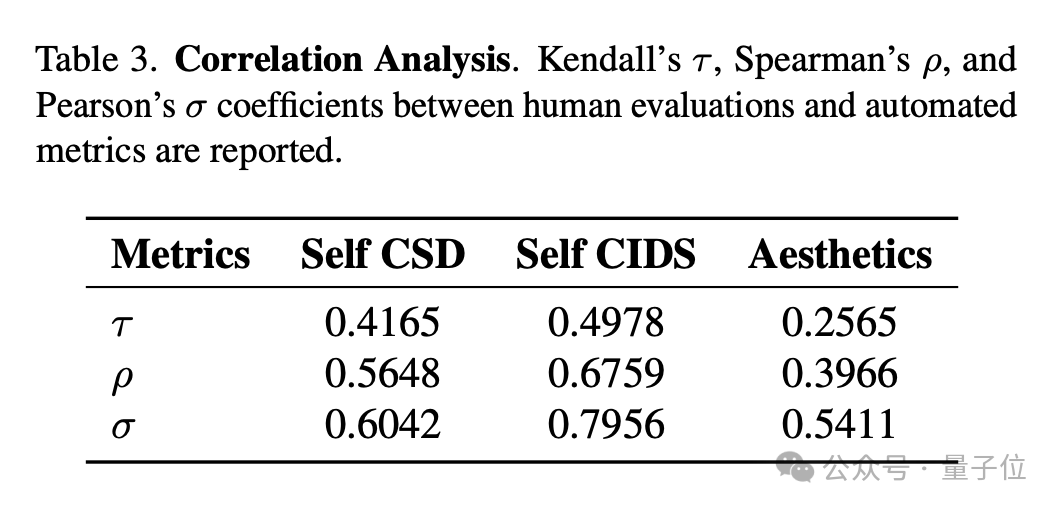
通过统计分析自动化指标与人工评估结果(用户研究)的相关性,团队发现自动化评估体系能够有效反映人类主观判断。
具体数据显示,Prompt Adherence指标与CIDS的相关系数达到0.6759,Aesthetics评分与CIDS的相关系数更是高达0.7956,这表明自动化评估指标具有较好的效度。
实验结果表明,该综合评估方案能够有效诊断各类模型的性能特征,为技术迭代提供了明确的优化方向。
然而,由于当前技术限制,局限性仍然普遍存在:
当前技术前沿限制:目前ViStoryBench专注于多图像的帧间一致性(inter-frame consistency),而非同步音视频电影的生成。未来团队将拓展至更复杂的视听同步叙事。
背景参考能力缺失:现有开源方法不支持背景参考图像,因此场景级一致性未被纳入评估。这限制了基准在完整环境渲染方面的全面性。
角色参考图偏差:部分方法使用非标准次生参考图像(额外生成的图像)进行特征提取,并非来自数据集中的原生图像,可能影响Cross-CIDS指标的准确性评估。
评估策略的权衡:采用的混合评分方案结合了专家模型(如CSD和Grounding DINO)来保证稳定性和连贯性,以及视觉语言模型(VLM,如GPT-4.1)来实现更丰富的语义理解。专家模型在复杂场景下可能表现不佳,而VLM容易产生幻觉(hallucinations),尽管团队努力选择可靠方法,但这些内在局限仍然存在。
版权限制:部分数据集图像源自电影、电视或动画(如知名作品),仅用于学术研究,但存在版权风险(fair use原则),用户需注意法律约束。
数据偏好:过度依赖知名内容可能导致评估指标对特定数据分布产生偏好,存在被针对性优化以及被操纵或“黑入”的风险。
ViStoryBench作为一个长期项目,未来会持续将最新的模型和技术方案纳入测评基准,感兴趣的朋友可以保持关注~
项目主页:https://vistorybench.github.io
展示窗:https://vistorybench.github.io/story_detail
技术报告:https://arxiv.org/abs/2505.24862
数据集:https://huggingface.co/datasets/ViStoryBench/ViStoryBench
代码:https://github.com/vistorybench/vistorybench
文章来自于微信公众号“量子位”。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


