3 月 16 日,在刚刚结束的 NVIDIA GTC 2026 大会上,黄仁勋在长达三小时的 Keynote 演讲中发布了 NVIDIA Agent Toolkit 和 AI-Q 开放智能体蓝图,将 AI Agent 定位为下一个重大前沿。引人注目的是,NVIDIA 在展示 AI-Q 的深度研究能力时,选择了 DeepResearch Bench 和 DeepResearch Bench II 作为评测标准 ——AI-Q 在两个榜单上均登顶第一,分别取得 55.95 和 54.50 的成绩。
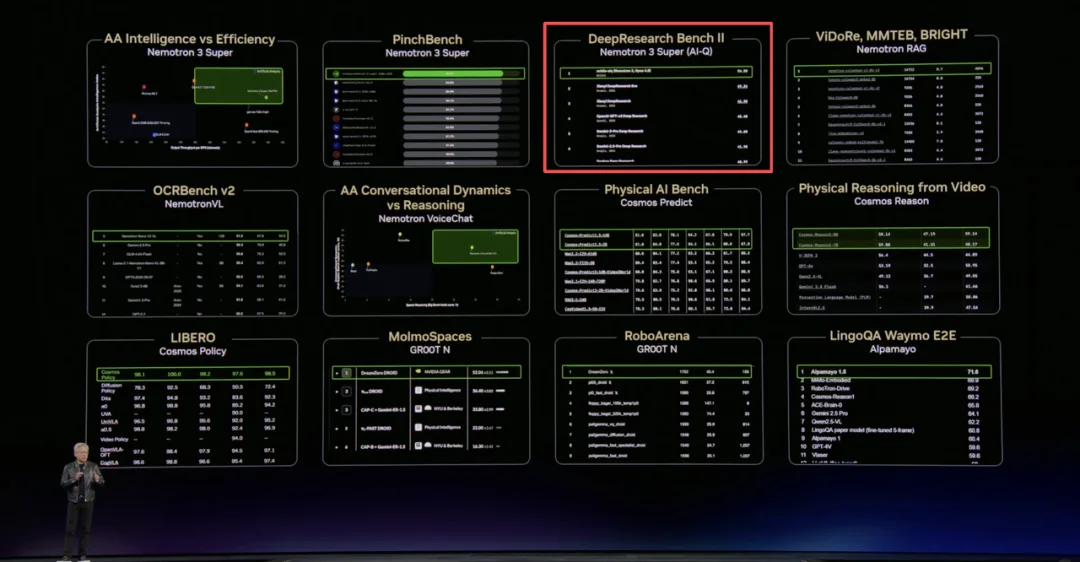
这两个基准是什么?为什么 NVIDIA 选择了它们?它们是如何设计的?背后又有怎样的思想演进?
背景:深度研究 Agent 的爆发与评估困境
自从 OpenAI 发布 Deep Research 以来,Google、Grok、Perplexity 以及国内的千问、字节豆包、通义等厂商迅速跟进,竞相推出各自的深度研究 Agent 产品。这是继 Cursor 之后,又一类被广泛验证有效的 AI Agent 应用 —— 它们能够自主规划搜索路径、浏览数十乃至上百个网页、提炼关键信息,将原本需要数小时的案头调研压缩到几分钟内,输出一份结构完整、引用丰富的研究报告。
但随之而来的问题是:这些报告到底写得好不好?不同产品之间的差异在哪里?该如何衡量?
评估深度研究智能体的难度,远超代码生成或数学推理 —— 后者有唯一正确的答案,而一份好的调研报告需要同时满足信息全面、分析深入、结构清晰、引用可靠等多重要求,这些维度之间还存在微妙的权衡。现有的评估方式要么只测智能体能否找到特定事实,却不关心它能否决定 "该找什么" 以及 "如何整合成连贯叙述";要么评估完整报告,但标准过于粗放或完全由 LLM 自行定义 —— 相当于让考生自己出题再自己打分。
来自中国科学技术大学的研究团队围绕这一问题展开了系列工作,先后推出了 DeepResearch Bench 和 DeepResearch Bench II 两代评估基准。所有数据、代码和评估脚本均已开源:

DeepResearch Bench(ICLR2026):
- 论文链接:https://arxiv.org/abs/2506.11763
- GitHub:https://github.com/Ayanami0730/deep_research_bench

DeepResearch Bench II:
- 论文链接:https://arxiv.org/abs/2601.08536
- GitHub:https://github.com/imlrz/DeepResearch-Bench-II
DeepResearch Bench:
第一个系统性评估框架
从真实需求出发
研究团队认为,这类 Benchmark 应该服务于真实的用户需求。为此,他们收集了一个包含约 9.6 万条用户查询的内部数据集(来自用户与搜索增强型 LLM 的真实交互),经过数据脱敏、过滤和分类,最终获得 4.4 万条符合 "深度研究" 定义的查询,并统计出用户在 22 个主题领域上的真实需求分布。
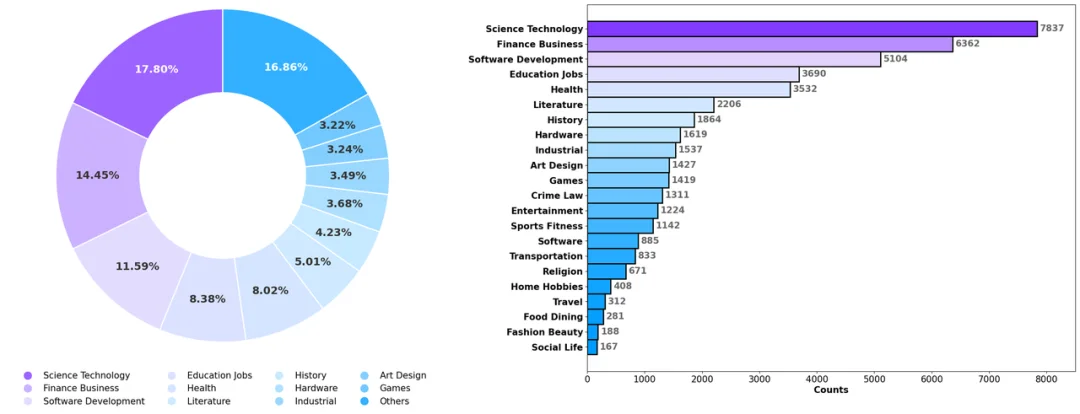
基于这个分布,团队确定了每个领域的任务数量,并邀请相关领域的博士级专家编写调研任务,最终构建了一个包含 100 个高挑战性研究任务(50 个中文 + 50 个英文)的基准数据集。
两个互补的评估框架
该工作设计了两个评估框架,分别回答关于调研报告的两个本质不同的问题:
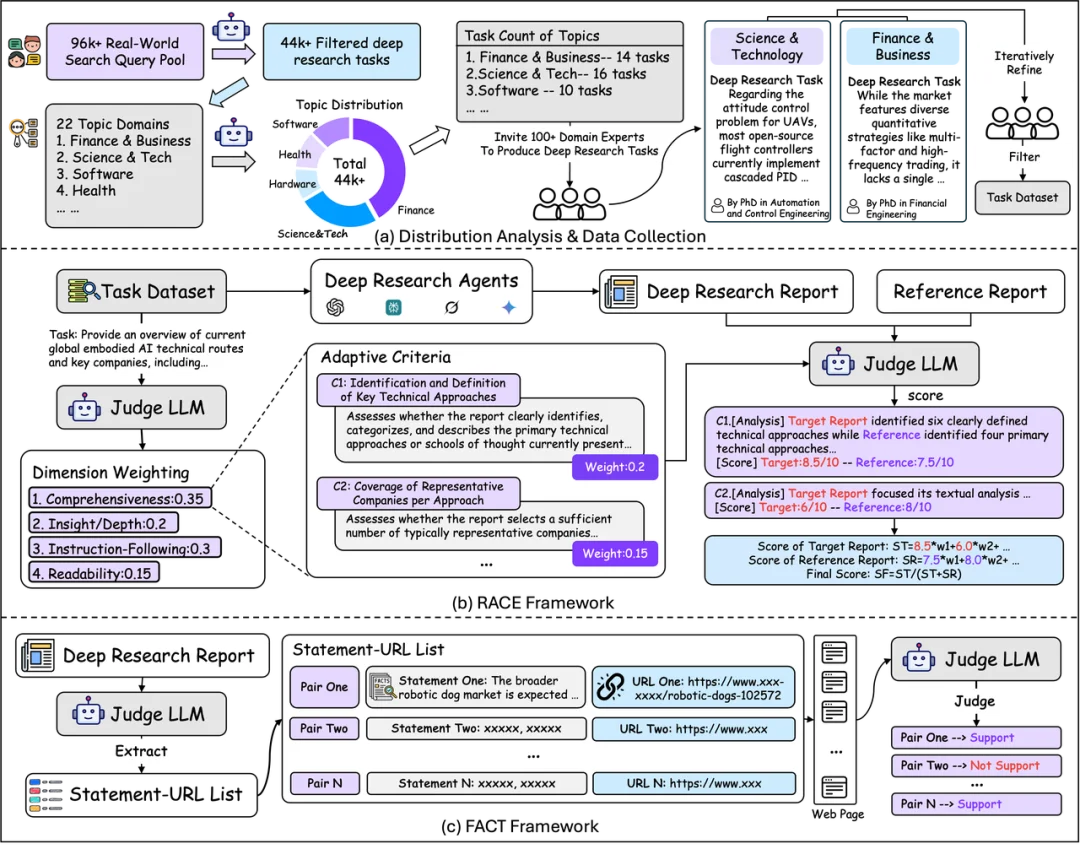
RACE:报告质量怎么样? 核心思想是不同任务的评估侧重点应该不同 —— 金融分析任务显然比历史概述更看重数据深度,面向大众的科普任务则更看重可读性。RACE 根据任务特点动态生成评估标准(criteria)和权重(weight),然后引入一篇高质量参考报告进行对比评分,避免 LLM 评审倾向于 "一律给高分" 的问题。
FACT:检索到的信息靠不靠谱? 从报告中提取每一条事实声明及其引用的 URL,抓取对应网页内容后,逐条验证引用是否真正支持该声明。由此量化两个关键指标:智能体引用了多少 "有效信息"(E. Cit.),以及引用的准确率有多高(C. Acc.)。
关键发现
在首批评估中,团队测试了多个深度研究产品和搜索增强型 LLM。Gemini Deep Research 和 OpenAI Deep Research 展现出明显的领先优势,但各有侧重:前者在全面性和有效信息量上遥遥领先(平均每个任务 111 条有效引用),后者在指令跟随能力上更为出色。Perplexity Deep Research 虽然总体排名稍低,但引用准确率高达 90%,远超其他竞品 ——"找到多少" 和 "找得准不准" 是两种截然不同的能力。
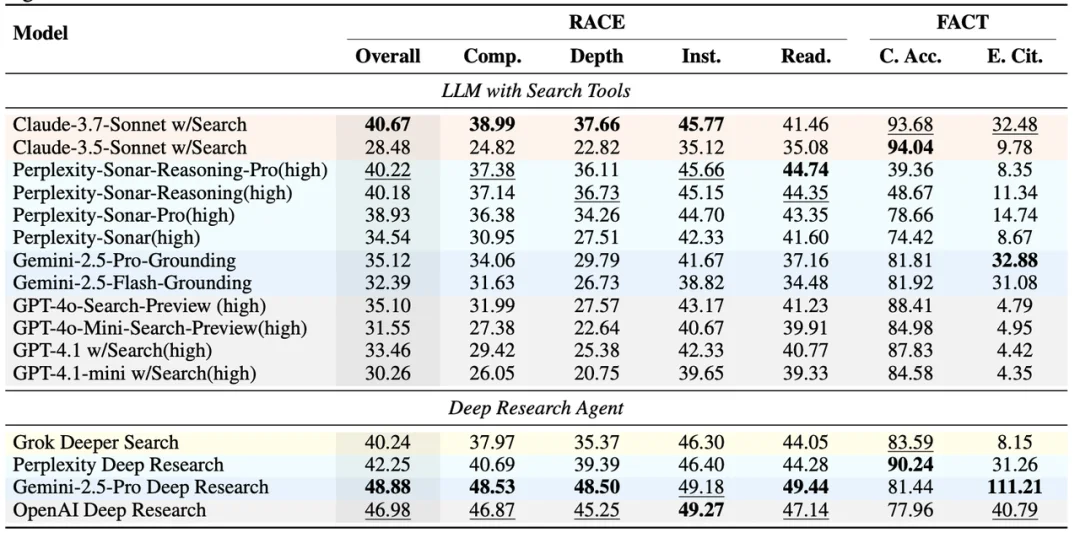
团队还使用 50 个中文任务进行了人类一致性实验,每个任务邀请 3 位相关专业的硕博志愿者对四个模型的报告打分,总计 225 人时的评分工作。最终验证 RACE 的成对一致率达到 71.3%,超过了人类专家之间的互评一致率(68.4%),大幅优于基线 LLM-as-a-Judge 方法及 RACE 自身的任何消融变体。
DeepResearch Bench II:
用专家标准丈量 AI 的真实差距
现有评估范式的两个根本问题
DeepResearch Bench V1 发布后,后续出现的深度研究评估基准基本都沿用了两类思路:
其一,先验的评分点。 由 LLM 预先生成一组评估标准,据此对报告打分。但这套标准本身就是 LLM 自己定义的 —— 模型认为重要的内容,未必是领域专家真正关心的。
其二,后验的引用审查。 检查引用是否有效、能否支撑报告中的结论。但引用格式正确、来源可访问,并不意味着内容本身就是对的 —— 模型从开放网络中检索到的信息,有可能本身就是错误信息,甚至是针对 AI 的数据投毒。
核心判断:评估终将回归到与人类专家的对齐
对于第一个问题,研究团队提出了自己的判断:尽管当前模型还有通过自我评估、自我迭代来提升的空间,但随着模型自我演化能力不断增强,自我生成和自我验证终将达到一个平衡点。届时,评估的核心问题将变成:模型认为一份调研报告应该包含的内容,是否真的与人类专家的预期一致?
要回答这个问题,就必须以人类专家作为参照。而开源的、经过同行评审的人类专家调研报告,正是绝佳的锚点。
引入人类专家报告之后,第二个问题也随之解决 —— 专家文章中本身就包含了正确的证据和结论,只需要检查模型的报告中是否涵盖了这些内容即可,不再需要依赖对网页引用的逐条验证。
逆向解构:从专家报告到评估标准
一份调研报告的生成过程是正向的:确定研究问题 → 召回信息 → 分析 → 组织呈现。而 V2 的做法恰好相反 —— 从专家已完成的报告出发,逆向解构出它是如何呈现的、如何分析的、召回了哪些信息、研究问题是什么,据此提取出评估标准(rubric)和调研任务。
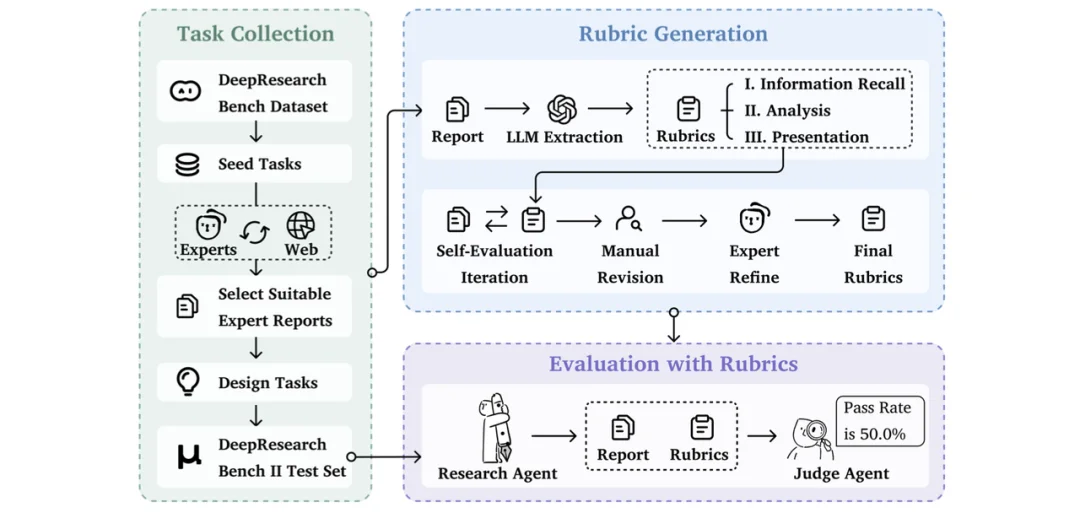
具体而言,团队从知名期刊、顶级会议和权威机构出版物中精选了 132 篇高质量研究文章(均为 CC-4.0 或 CC-4.0-NC 许可),通过 "LLM 提取 → 自我评估过滤 → 人工修订 → 领域专家精炼" 的四阶段管线,最终获得 9,430 条细粒度二元 rubric(平均每个任务约 71 条)。这些标准不是抽象的 "是否全面" 或 "分析是否深入",而是诸如 "是否指出小城市劳动力流失的关键原因在于职业结构错配" 这样可以直接回答 "是或否" 的具体要求 —— 评估模型不需要依赖自身的领域知识来判断对错,标准本身已经编码了答案。
三层能力解剖
在评估维度上,V2 从信息组织的视角出发,将深度研究任务拆解为三层递进的核心能力:
- 信息召回:Agent 是否知道该找哪些信息?找到的信息是否正确?这是研究流程的基础。
- 分析:Agent 能否超越简单的信息汇总?现实中,很多模型给出的调研报告往往只是引用一些现成的结论,或给出聊胜于无的弱结论,而缺乏真正从原始信息出发、通过推理和综合得出有价值的高层次结论。
- 呈现:即使信息正确、结论有价值,如果不能以清晰、用户友好的方式组织和传达,同样不能算一份好的调研报告。
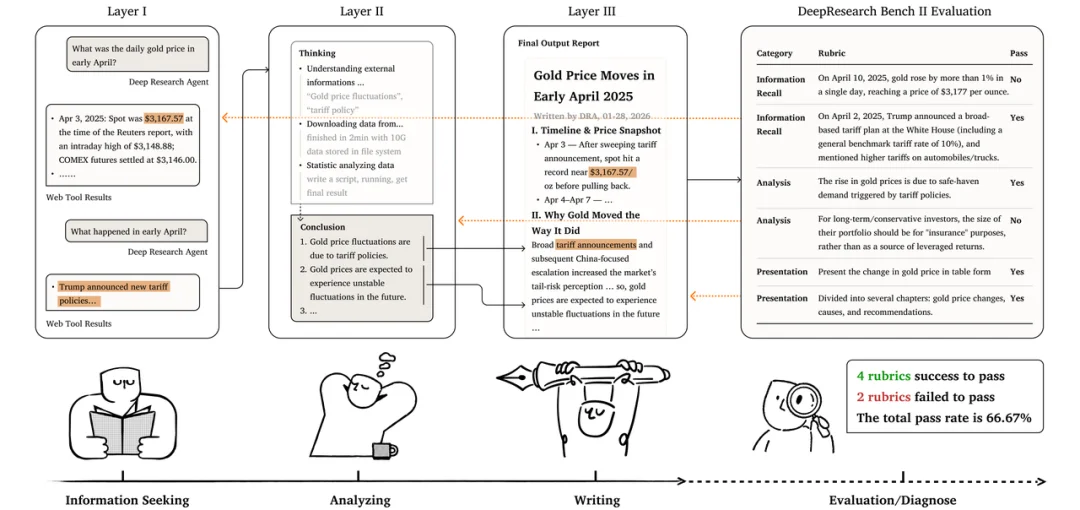
这三层对应了深度研究从 "搜索" 到 "思考" 再到 "写作" 的完整链条。
两代工作的思想脉络
回顾这个系列,核心追问始终是同一个:如何让对深度研究 Agent 的评估更接近人类专家的判断?
第一代的答案是 "让评估更智能"—— 通过动态权重、自适应标准和参考对比,使 LLM 评审能够灵活地判断报告质量,并取得了超越人类互评一致率的结果。
第二代的答案则是 ——"让评估有据可依"。与其让 AI 自行判断什么是好的研究,不如直接以人类专家的研究成果为标杆,将 "好" 分解为数千个可验证的具体要求。这不仅使评估更加客观透明,也首次实现了对 AI 与人类专家之间差距的精确定位。
两代工作共同构成了一个从 "能不能评" 到 "评得准不准" 再到 "差距在哪里" 的完整叙事。而 NVIDIA AI-Q 的最新结果表明,这把标尺正在被行业头部玩家采纳,用于度量和推动 AI 深度研究能力的边界。
局限与展望
研究团队也坦诚地讨论了当前工作的不足。
即便是人类专家撰写的调研报告,也不可能让所有读者满意。这恰恰说明评估深度研究智能体本身就是一个带有主观性的长尾问题 —— 当前的评估方法只能尽力使其与大多数人的价值判断和信息需求保持一致。同时,由于专家文章本身可能存在瑕疵、LLM 提取过程中可能产生幻觉、人工校验也难免有所疏漏,rubric 并非完美无缺。为此,团队在项目主页设置了公开的评论区,欢迎社区的指正与讨论。
向前看,该系列的评估揭示了一些不会很快消失的根本性挑战:
- 分析的深度与原创性:从信息汇总到真正的洞察之间,仍然存在一道鸿沟 —— 即便是突破 50% 的 AI-Q,其分析维度也仍有巨大提升空间
- 用户适应性:同样的研究主题,面向本科生和面向资深教授的报告应该截然不同,但当前系统几乎无法做到这种自适应呈现
DeepResearch Bench 系列的所有数据、代码和评估脚本均已开源(链接见文首)。
作者简介:
本文作者团队来自中国科学技术大学。DeepResearch Bench 第一作者为杜铭轩,DeepResearch Bench II共同第一作者为杜铭轩、李睿哲。合作者为徐本峰、朱池苇、王晓瑞。通讯作者是中国科学技术大学教授毛震东。
文章来自于"机器之心",作者 "机器之心"。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/

