超级个体是一种底层人格结构。

1997 年,Steve Jobs 以 Internship CEO 的身份回归到 Apple 后,亲手撰写并配音朗读了 Think Different 广告词。
在笔者看来,在 30 年前 Steve Jobs 就已经给“超级个体(Super Individual)”下了一个最贴切的定义,The Crazy Ones。

前言
思想实验
让我们来做一次有趣的思想实验: - 👨🏻💻 如果 2024 年底,Claude Code 创始者 Boris Cherny 和 Cat Wu 在你的部门任职,刚入职不久的他俩打算做一个只能跑在命令行里的 Coding Agent——Claude Code,你的部门会同意吗? - 🦞 如果 2025 年底,OpenClaw 创始者 Peter Steinberger 在你的部门工作,提出要做一个 7x24 小时的 OpenClaw,你所在的组织会 Sponsor 他吗?会让他一个人做一个项目/产品吗?
大家最容易误判的一句话,是“我们要培养超级个体”。
这句话听起来很与时俱进,但是背后还是旧世界的想象:
把员工送去上课,给他一套 AI 工具,制定一些 AI Adoption Rate 的 KPI,发几张证书,再把他放回原来的岗位、原来的职责、原来的汇报链条里,期待他自然长出十倍产出,因为 Anthropic 说他们做到了。
笔者的判断相反:超级个体不是被培训出来的,而是被好奇心激发出来的。
一个人有没有可能变成超级个体(Super Individual),不只看他能力强不强。更关键的是,他有没有强好奇心,愿不愿意探索未知,能不能自学,能不能自驱,能不能把一个模糊念头亲手做成一个可用的东西。换句话说,超级个体不是“更强的岗位人”,而是一能够重新拿回完整 Closed-loop 的人。有同学提到了 FDE,可以参考我的这篇文章 FDE——AI 时代的职业转型已经打响?[1]
今天,笔者更愿意称这群人为 AI Builders,而不是“超级个体”这类流行词。因为长期参与开源与社区,笔者有幸在工作中接触到许多符合“AI Builder”画像的人。他们曾经看起来都只是普通人:开发者、测试、产品经理、设计师,甚至是 HR、BD、VC 投资人。但他们身上有一个非常相似的特质:当他们聊起自己正在做的 AI 作品时,总会不自觉的滔滔不绝。那一刻,你很容易看到他们眼里的光。那不是对新技术的短暂兴奋,也不是对风口的投机热情,而是一种更朴素、更持久的东西:他们真的想把一个东西做出来,想 make it run,想让它被真实的用户所使用,想亲手参与这个时代正在发生的变化。
这也是本文的读者定位。这不是写给工程师看的 AI Coding 教程,也不是写给创业者看的个人 IP 手册。它更想写给 HR、OD、组织研究者、人才发展负责人和大型公司管理者:当你们讨论“AI 时代的人才战略”时,真正要问的不是“谁会用 AI”,而是“组织有没有允许一个人从问题发现,一直走到拿到结果”。
旧岗位人的日常,常常是这样的瀑布流中的一环:
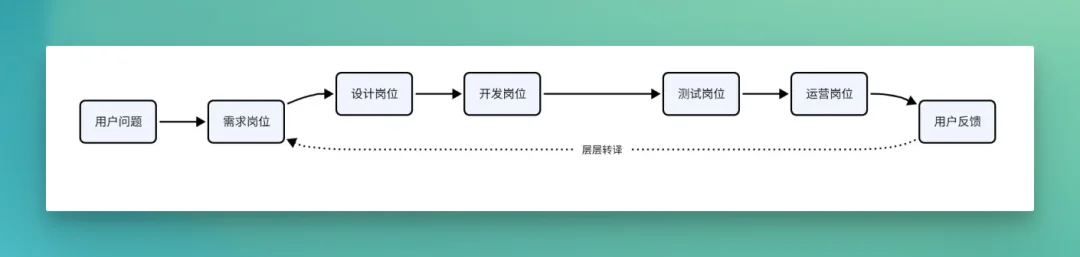
图中的瀑布式流程曾经是工业化互联网的效率来源。问题是,当 AI 把调研、原型、编码、测试、文案、数据分析这些能力重新压缩到一个人身边时,上边那套岗位切分就会开始变成阻抗。人的能力明明已经被工具放大了,组织却仍然把他切成一个局部函数。
这就是本文的核心矛盾:大公司不是没有人才,而是岗位设计把人切碎了。

正如 Steve Jobs 在 Think different campaign[2] 里写的,用很短的词描绘过一类人:misfits、rebels、troublemakers,以及那些 see things differently 的人。笔者不想把这段文案神化。它真正有价值的地方,是提醒组织不要只用“合规的人才模型”理解创造力。很多推动新生产关系的人,天然就是“方孔里的圆钉”。他们不一定最会写 OKR 汇报,不一定最擅长对齐,但他们会自己动手,会绕过惯性,会把一个没人立项的问题做成东西。
你知道吗——Naval 的三种杠杆?
Naval Ravikant 在 The Almanack 里把商业杠杆分成三类:劳动力、资本,以及“没有边际复制成本的产品”。代码和媒体属于第三类,几乎是 permissionless 的,个人就能启动;劳动力和资本则仍然需要组织承载。也就是说,组织没有消失,它只是必须学会和新的个体杠杆重新配合。参见 Find a Position of Leverage[3]。
所以,这篇文章不讨论“如何把每个员工都训练成超级个体”。那仍然是流水线思维。
它也不把超级个体理解成某种个人品牌人设。真正值得组织关心的,是一个人能不能把好奇心变成行动,把行动变成作品,把作品交给真实用户,再把反馈吃回自己的判断系统里。这是一种 Closed-loop 行为,不是一张能力标签。
本文真正要讨论的是另一件事:如果超级个体的原料本来就散落在大型公司内部,组织怎样提供土壤,让这些人被完整 Loop 激发出来。
因为 Closed-loop 不是 AI 发明的,AI 只是让一种旧能力重新变得可规模化。
答案要从一个看似很远的时代讲起。那时还没有 LLM,没有 Agent,没有组织级中台,甚至很多人还在拨号上网。但那个时代的程序员,反而比今天很多大厂员工更像完整的人。
前史

我在 2002 年读本科。那时中文互联网还不大,软件世界却很热闹。宿舍里最常见的场景,是有人从《电脑报》附带的光盘里翻工具,有人去华军软件园、天空软件站找新版本,有人把一个压缩包拷到 U 盘里到处传。一个软件好不好,不靠发布会,不靠增长团队,不靠买量。它靠论坛口碑、下载站推荐、杂志编辑试用,以及用户之间一句“这个好用”。
今天回头看,那是一个百家争鸣、光怪陆离的时代:很多程序员天然就是六边形战士,谁不是“一人公司”。
他先从自己的痒点出发,发现一个问题;然后自己设计界面、设计 Logo,自己写代码,自己打包发布,自己写说明文档,自己去论坛回答用户反馈的问题,自己看用户骂哪里难用,自己给软件下载站和电脑杂志发邮件。再小一点的团队,甚至宣传文案、Logo、FAQ、安装包、用户群维护,全都在同一个人或两三个人手里。
这不是因为他们学过“产品经理能力模型”。恰恰相反,那个时候很多岗位还没有被正式命名。产品感、设计感、工程能力、传播意识、用户反馈,是在一个真实 Closed-loop 里长出来的。
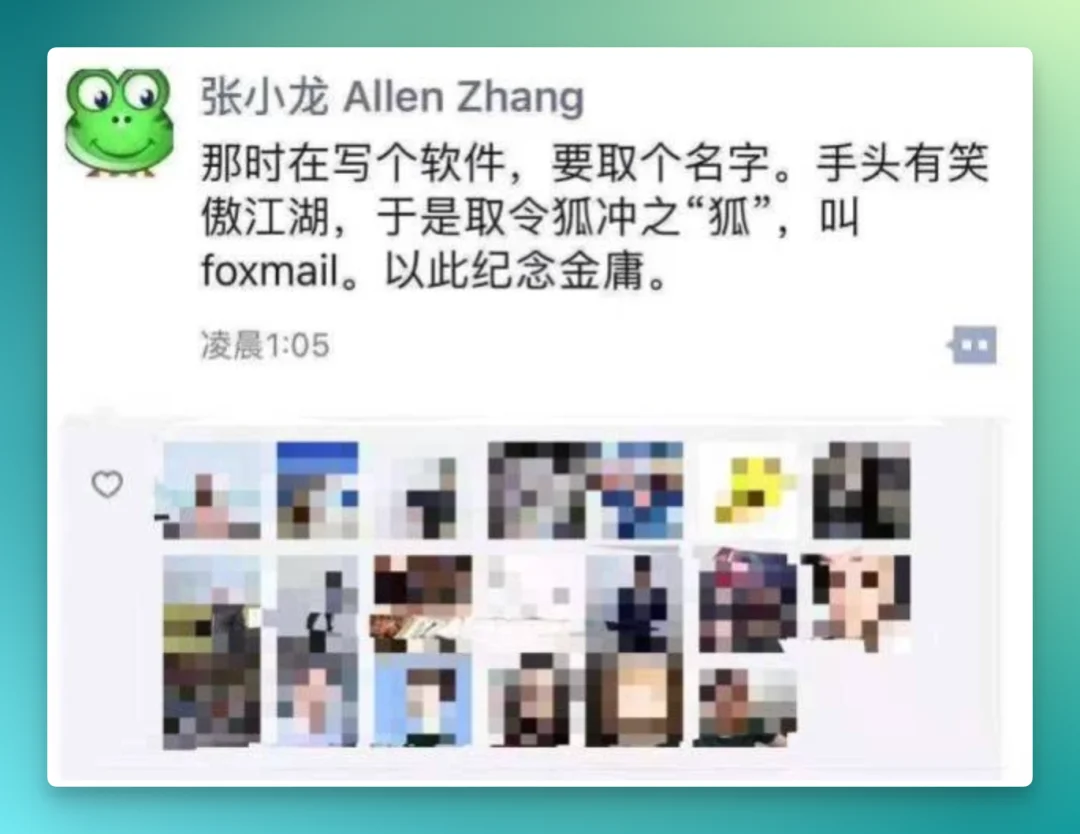
国内有很多这样的样本。张小龙的 Foxmail 是最典型的一个:新浪 2001 年对张小龙的专访里,仍把 Foxmail 放在“国产共享软件”的语境里讨论,并提到 Foxmail 4.0 的免费策略和当时的用户规模。后来界面新闻回顾 Foxmail,也明确写到它在 1997 年上线,诞生起就定位为免费软件。更稳妥地说,它是国产共享软件/免费软件语境里的代表样本。链接可以看 新浪科技旧文[4] 和 界面新闻回顾[5]。
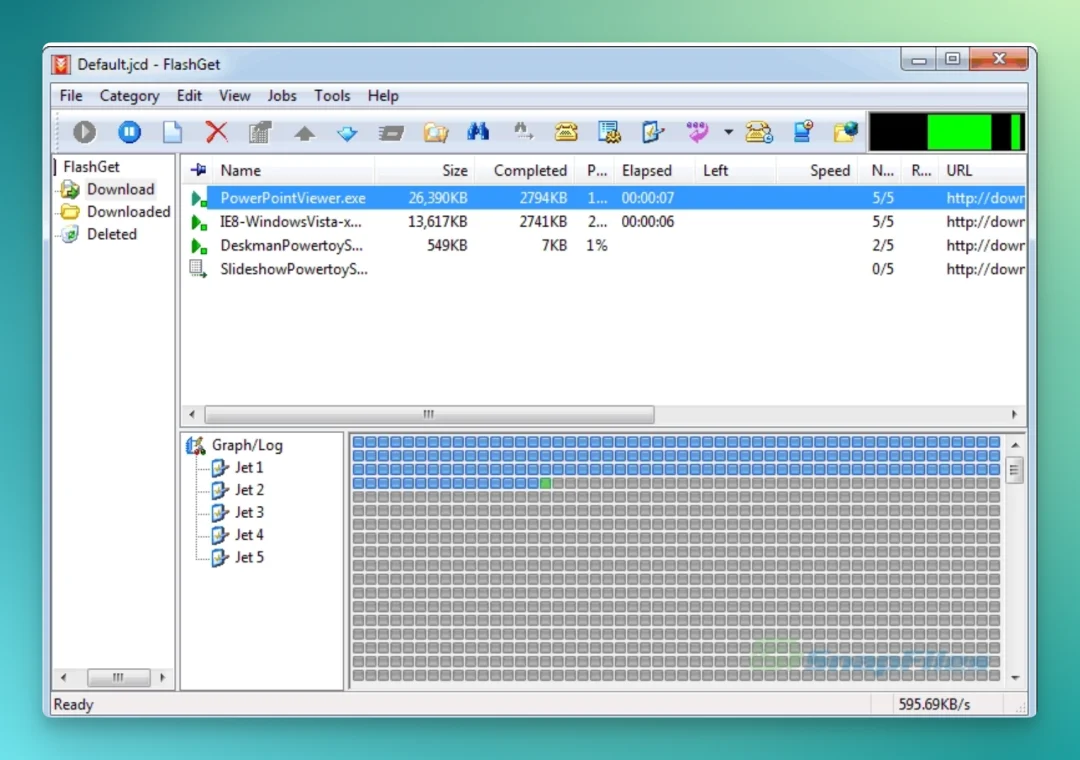
FlashGet 也类似。官方十周年页面写得很清楚:1999 年 JetCar 问世,2000 年更名为 FlashGet,靠多线程下载和文件管理能力切中拨号上网时代的痛点。见 FlashGet 十周年大事记[6]。

国外也一样。WinZip 的前身 Nico Mak Computing,官方页面写到它在 1991 年由 Nico Mak 创立;ACDSee 官网回顾里说,第一版 ACDSee 在 1994 年通过 BBS 分发,售价 15 美元;Winamp 通常被追溯为 Justin Frankel、Dmitry Boldyrev 等人在 1997 年发布的播放器,后来成为 MP3 时代的标志性软件。分别见 WinZip 的 Nico Mak Computing 回顾[7]、ACDSee About[8] 和 TechSpot 的 Winamp 回顾[9]。
笔者有幸经历了那个年代,并且在 2002 年写了自己第一个破万的 Shareware —— MagicCube Lyric Editor[10],这是一个可以自动寻找、下载和编辑 MP3 内嵌歌词、自动上传到 MP3 播放器(硬件)的解决方案,当时自己做了产品设计、编程开发、打包发布和媒体投稿宣发,并且也因为这个软件得到了第一份实习工作。
为了不流失青年读者们,笔者不再举这些“登味儿十足”的例子。这些例子也不必被过度的神话和浪漫化。那个独立软件/共享软件混杂的时代,也有粗糙、盗版、商业化困难、支持成本高的问题。很多作者既没有稳定收入,也没有今天成熟的协作工具。
但它给我们留下了一个重要启发:超级个体不是 AI 时代才突然出现的人种。
当年的“作者”往往不是单点能力最强的人,而是最愿意探索、最有开源共享精神、最能自学、最能动手、最能把用户反馈接回自己脑子里的人。他不是在岗位描述里被定义出来的,而是在完整 Closed-loop 里被迫长出来的。
你知道吗——Shareware 作者为什么天然是多面手?
Shareware 的核心不是“免费试用”这么简单,而是作者直接面对分发、收费、用户支持和口碑扩散。没有独立 PM 帮他写需求,没有 UX 团队帮他做访谈,也没有运营团队替他经营社区。 Closed-loop 越短,人的综合能力越容易被激发出来。
所以,当今天我们重新讨论超级个体,不应该只看 AI 把个人能力放大了多少。更应该看见一个历史回声:一旦组织或市场把完整 Closed-loop 交还给个人,个人就会长出超出岗位的形态。
后来的互联网工业化,做的事情正好相反。它用效率的名义,把这个曾经单一的程序员岗位一点点拆开了。接下来二十年,组织为了规模化交付,把这种 Closed-loop 拆成了专业岗位。
拆分

2006 年之后,互联网开始进入另一种叙事:更大的流量,更复杂的业务,更细的岗位,更强的平台。
这当然是进步。没有分工没有岗位化,就没有大规模协作;没有工业化,就没有稳定交付;没有平台化,就没有复杂业务的可治理性。一个人的角色被拆成了岗位人。
先看一条粗线。
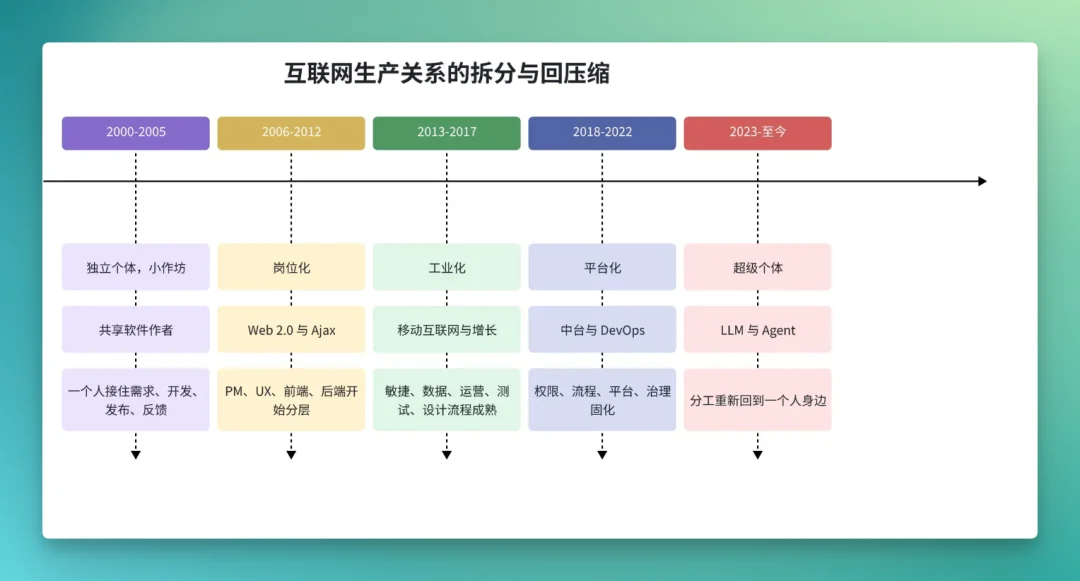
第一阶段,是 2006—2012 的岗位化。
Web 2.0、Ajax、浏览器能力提升,让网页从“页面”变成“产品”。复杂度一上来,角色自然分化:产品经理写 PRD,交互设计画流程,视觉设计做稿,前端实现页面,后端提供接口,测试保证质量,运营负责增长。每个岗位都开始有自己的方法论、Job Grade、晋升通道和专业话语。
但这里有一个很容易被忽略的细节:2010s 左右,产品经理这个岗位的原始定义,本来就很接近今天人们所说的超级个体。
那一代产品经理被期待理解用户、洞察需求、设计流程、推动研发、协调设计、盯上线、看数据、听反馈,甚至要会讲故事、会写文档、会做增长,诞生了数据驱动的增长黑客理论。换句话说,组织已经隐约意识到,需要有一个人把被拆开的产品闭环重新抓在手里。只是那个时代的产品经理没有 Claude Code,没有能直接改代码、做 Demo、跑测试、生成页面、调度 Agent 的执行武器。他能负责闭环,却很难亲手闭环。
这件事提高了效率,也制造了第一层切断。一个工程师不再天然面对用户,一个设计师不再天然关心发布,一个产品经理也可能不再亲手触摸实现成本。组织获得了专业化,却失去了一部分人的整体感。
第二阶段,是 2013—2017 的工业化。
移动互联网把节奏推到极致,产品经理成为这个时代的王者。在“增长黑客”精神的带领下,App 版本、渠道投放、埋点分析、A/B Test、增长漏斗、敏捷迭代、持续集成,开始成为大型公司日常。岗位不只是分开,还被流程串起来。一个需求从提出到上线,要经过评审、排期、开发、联调、测试、灰度、复盘。
这时的组织已经很像工厂车间流水线。每个环节都更专业,每个角色都更可替换,每个项目都能被排进资源池。代价是,很多人开始只对自己负责的片段负责。用户的痛点在文档里,产品的成败在指标里,真实反馈被清洗成报表。
第三阶段,是 2018—2022 的中台化。
这一段常被简单写成“中台热”。但笔者觉得,更准确的说法是:组织开始用平台、权限和治理,把前面十几年的复杂度固化下来。
业务中台、数据中台、技术中台、低代码平台、DevOps 平台、权限系统、合规流程、发布管控、工单系统,一层层叠起来。它们本来是为了解决重复建设和风险治理,最后也变成了新的组织边界。你想做一个小实验,可能先要申请数据权限;想调一个接口,可能要找平台 owner;想上线一个灰度,可能要排进发布窗口;想碰用户反馈,可能要经过客服、运营、数据团队的层层转译。笔者这段时期正好在国内最推崇“中台化”的大厂里做研发 leader,在中台技术如日中天的时候,超级个体几乎灭绝了,取而代之的是“螺丝钉”们。
这就是平台化的悖论:平台降低了标准动作的成本,却提高了非标准探索的成本。而今天大家在讨论的 Agent 范式就是非标探索。

Melvin Conway 在 1968 年的文章 *How Do Committees Invent?*[11]里提出过一个后来被软件工程反复验证的判断:一个系统的设计,会不可避免地映射出设计它的组织沟通结构。换到大厂语境里,就是岗位怎么切,产品就会怎么切;权限怎么分,系统边界就会怎么长;汇报链条有多长,用户反馈抵达决策者就有多慢。所以或许公司培养不出超级个体,不只是人才问题,而是组织结构本身在持续生产“局部人”。你让一个人负责局部,他就会只优化局部;你让一个人只能通过接口、工单、会议和评审触达别人,他最后做出来的产品也会长得像接口、工单、会议和评审。60 年过去了,康威定律仍然能够解释我们今天产品和组织设计的对应关系,无论是组织里做的好的还是待改进的部分。
你知道吗——DevOps 本来不是“更多平台”的同义词?
DevOps 的原始精神,是缩短开发、运维和用户反馈之间的距离,让团队对交付结果负责。可是在很多大厂里,它最后被实现为一组平台、审批和权限系统。工具越强, Closed-loop 未必越短;治理越完整,个人越可能离真实问题更远。
到这里,过去的独立个体职能已经被拆得差不多了。
好奇心被拆给了创新部门,探索被拆给了预研项目,自学被拆给了培训体系,自驱被拆给了绩效目标,动手能力被拆给了岗位职责。人还在变强,但强在局部;组织还在变稳,但稳在流程。后端不再知道自己的 API 在网页上是如何被渲染出来的,前端不再关心高并发高可用性,研发不懂测试,研发抱怨产品经理不懂技术,产品经理抱怨技术不懂用户需求、动作太慢赶不上竞争对手。
当我们站在 2026 年的今天回过头来看时,这就是为什么 AI 的冲击这么反直觉。真正的新变量,是工具第一次开始系统性降低跨岗位行动的成本。LLM 和 Agent 不是简单提高某个岗位的效率,而是把被拆开的能力重新推回一个人身边:一个产品经理可以直接做原型,一个设计师可以直接跑交互 Demo,一个前端可以直接完成调研和文案,一个运营可以让 Agent 帮他分析数据、生成页面、组织发布。
问题随之而来:当工具已经开始压缩分工,组织还要不要继续用旧岗位、旧权限、旧流程把人切开?
如果答案仍然是“要”,那大公司会看到一种奇怪的景象:员工明明在外部工具里越来越完整,回到公司内部却越来越局部。超级个体不是没有出现,只是被组织结构重新压回了岗位人。
回潮

2023 年之后,变化不是“多了一个聊天机器人”。真正的变化是:LLM 和 Agent 开始重新压缩分工。
前面的历史已经说明,岗位化、工业化、平台化都有自己的合理性。它们解决了规模协作,也把人的完整感拆成了一个个局部函数。
AI 的新变量在于,它不是给每个局部函数装一个效率插件,而是把跨岗位行动的成本突然打低。LLM 出现以后,这个结构开始回潮。
•一个前端可以用 Claude Code、Cursor、v0 或者一组 Agent 在一天里做出能点、能试、能改的产品原型。
•一个 PM 可以把需求写成 issue,再让 Claude Code 读代码库、改页面、补测试、发 PR。一个设计师不再只交静态稿,而是可以做出带交互的 Demo,让会议从“想象它会怎样”变成“直接试试看”。
•一个普通员工也可以调度 Research Agent、Coding Agent、Test Agent、Deploy Agent、Release Agent,把一次调研、一次内部工具开发、一次上线说明和一次用户反馈收集串成一条线。
所以今天的变化,不是产品经理突然变重要了。产品经理一直重要。真正的变化是:过去产品经理只能用会议、文档和影响力调度闭环,现在他第一次有机会用 Agent 直接执行闭环的一部分。
这句话也适用于设计师、前端和运营。AI 不是让他们“跨岗越权”,而是让他们把过去只能靠沟通推动的东西,先做成一个可以被讨论、被试用、被反馈的具体对象。
这不是回到 2002 年。2002 年的完整个体,是因为系统还简单。一个人能从论坛、安装包、帮助文档、邮件反馈一路做到底,是因为软件生产链还没有被平台化、合规化、增长化、数据化切开。
今天的完整闭环不是靠“什么都自己干”,而是靠 AI 杠杆把执行层重新压缩到一个人的控制半径内。人不一定亲手写每一行代码,也不一定亲手做每一张图,但他重新拥有了从问题到结果的连续责任。
Agent 接走的是任务,不是责任。Research Agent 可以帮你扫资料,但不能替你判断什么问题值得做。Coding Agent 可以帮你改代码,但不能替你承担上线后的后果。Copy Agent 可以帮你生成文案,但不能替你面对用户误解。人重新站回闭环中心,是因为 AI 把大量“过去必须等别人排期”的环节变成了“现在可以先做一版”。
这也是为什么这一轮超级个体,不能只理解成能力强。能力强的人过去也有。AI 时代的超级个体更像五种力量的组合:好奇心强、探索和创新精神强、自学能力强、自驱力强、动手能力强。他不是先把课程学完再行动,而是在不确定里先搭一个小闭环,让现实给他回信。
换成组织语境,这类人未必真是麻烦制造者。他们只是更早看见旧岗位边界不够用了。
大型组织在这里最容易犯的错,是把这种回潮理解成“员工效率提升”。于是组织继续用旧岗位表述这件事:前端效率提升多少,PM 产出多少需求,设计师交付多少稿件,运营节省多少工时。
但更深的一层变化是:一个人可以重新拥有产品感。
产品感不是写 PRD 的能力,而是把用户痛点、可行方案、工程代价、交互手感、发布风险和反馈信号放在同一个脑子里滚一遍的能力。过去这种能力被分工拆散了。现在 LLM 和 Agent 把它又接了回来。
你知道吗——research preview 为什么不是营销词?
OpenAI 在 2022 年 11 月 30 日发布 ChatGPT[12] 时,明确称其处在 Research Preview 阶段:先让用户免费试用,收集强弱项反馈。这个标签的价值不只是对外降低预期,更是对内保护胚胎产品——它允许一个还不成熟的东西先出生、先被真实用户摸到、先从反馈里长大。
Research Preview 本质上是一种组织制度。
它告诉组织:有些东西不能等到商业计划、合规方案、体验规范、增长模型全部想清楚之后才发布。等你想清楚,它就已经不是那个东西了。LLM 产品尤其如此,因为模型能力本身还在快速变化,产品形态必须贴着能力边界长。
所以,“回潮”不是怀旧。它不是要取消专业分工,也不是要让每个人都变成全栈工程师、全能设计师、全能运营。它只是提醒大公司:AI 已经把很多旧分工的交易成本打下来了。一个人重新从前做到后,已经不是个人英雄主义,而是一种新的生产关系。
组织真正要问的,不是“员工有没有被培训成超级个体”,而是:我们有没有允许一个人先把闭环跑起来?
样本

为了说明“闭环激发”如何发生,可以看三类样本:内部原型、公众 Research Preview、个人开源 Agent。
Boris Cherny、Cat Wu 和 Claude Code 属于第一类;ChatGPT 的 Research Preview 属于第二类;OpenClaw 这类开源个人 Agent / personal assistant 项目属于第三类。它们放在一起看,表面上很散,但有一个共同形状:不是战略先行,而是个人先被痒到。
Pragmatic Engineer[13] 写 Claude Code 时,把 Boris Cherny 称为最早原型和项目的 Founding Engineer,把 Cat Wu 称为 Founding Product Manager。这个身份要写准:Cat Wu 不是“研究员”式的旁观者。她的价值不在于给一个技术玩具加包装,而在于把一个工程师的痒点翻译成产品判断。
Boris 最早只是想熟悉 Anthropic 的公开 API,于是做了一个 terminal 里的小工具。它能通过 AppleScript 看当前播放的音乐,也能换歌。这个起点小到几乎不能立项:没有潜在市场分析,没有竞品分析,没有季度目标,甚至还没有“工程效率工具”的自觉。
然后它接上文件系统,接上 bash,开始读代码库、跑命令、追上下文。模型能力突然被一个很朴素的产品形态接住了。Claude Code 不是从“我们要做一个 AI Coding 平台”开始的,不是被组织计划出来的产品,而是被超级个体玩出来的产品工具。相反它的后继模仿者则一定是被其他大厂计划出来的、多角色分工的产物。
ChatGPT 也是同一个形状的另一种版本。OpenAI 没有把 2022 年 11 月 30 日那次发布包装成一个完整消费级产品,而是用 Research Preview 让真实用户先进来。它的关键不是“发布了一个聊天产品”,而是组织允许一个不完整形态面对世界,并把世界的反馈变成下一轮产品定义。
OpenClaw 这类开源个人 Agent / personal assistant 项目,则提供了第三种样本。这里不强行断言某个项目的全部历史细节,因为开源项目的叙事经常被二级传播改写。但这一类项目的共同方向很清楚:OpenClaw[14] 这样把消息入口、文件、日程、邮件、脚本、长期任务接给 Agent 的产品,正在让 AI 从“回答问题”变成“替我做事”。它们往往不是从正式公司战略里长出来,而是从开发者对自己日常工作流的不满里长出来。
这就是超级个体的真实起点。
不是简历上写“能力强”,而是一个人对低效足够敏感,对未知足够好奇,对工具足够敢试,对失败足够不怕,对动手足够有冲动。他先做一个玩票 Demo,不是因为他已经想清楚商业模式,而是因为他不动手就难受。
你知道吗——Product Overhang 是什么?
在 Claude Code 的语境里,Product Overhang 可以理解为“模型能力已经超过现有产品形态”。模型已经能做一些事,但产品还没有给它合适的入口、权限、上下文和反馈回路。最先看见 Overhang 的,通常不是战略部门,而是每天被具体工作流磨到的一线人。
把这些样本抽象成信息流,会得到一条很短的链路。很多大公司也有个人痒点,也有玩票原型,也有自学能力很强的一线员工。区别在于,原型从个人电脑走到内部飞书,再走到团队采纳,再走到正式资源之前,会不会被旧流程杀掉。
旧流程会问一组非常熟悉的问题:这个归哪个部门?和现有项目冲突吗?谁来负责安全?今年 OKR 里有没有?没有设计稿为什么先写代码?没有用户研究为什么先发 preview?
这些问题都不是错的。问题在于,它们太早出现了。
胚胎产品最怕的不是质疑,而是在还没长出心跳之前,就被要求证明成年后的收入。Product Overhang 需要的是先让一小群真实用户摸到它,再看采纳曲线、抱怨、复用、误用和绕路行为。组织要做的不是替它写好商业计划,而是先别把它从土里拔出来检查根长得够不够标准。
换成组织语言,那些看起来像“方孔里的圆钉”的人,往往是旧格子装不下新闭环。大公司如果只把他们看成“不按流程来”的人,就会错过这轮 AI 工业革命里最早的一批传感器。
所以,样本给大公司的启发很朴素。
超级个体不是培养课上讲出来的。他们先以个人痒点出现,以玩票原型出现,以“不太像正式项目”的方式出现。组织能不能接住他们,取决于它是否允许好奇心、自驱、自学、探索和动手能力在 KPI 之外先长一段时间。
真正的问题不是“我们公司有没有 Boris”。真正的问题是:如果 Boris 已经在你的部门,他的 AppleScript 小玩具会不会活过第一周?
决定它能不能活过第一周的,往往不是技术难度,而是管理系统如何接收早期信号。
延迟

很多人把大型组织的 leader 们在 AI 里的延迟理解成态度问题:不够开放,不够年轻,不够懂技术。
对此,笔者不太同意。
笔者从 2007 年到 2024 年做了 17 年的 leader,先后在国内 2 家最顶级的大厂带过 70 多人的传统研发团队。
笔者认为更准确的说法是:leader 的时间结构、风险责任和评价指标,把他们放在了一个天然后知后觉的位置。这不是道德批判,而是组织结构造成的认知延迟。他们曾经是推翻“PPT 汇报”、推翻“瀑布式开发”、鼓励“数据驱动”的那一批先行者。
一线员工最先成为 Early Adopters,有一个很简单的原因:他们离痛点最近。
工程师每天被遗留代码、测试失败、文档缺失、重复 review 折磨。PM 每天在需求澄清、竞品调研、原型验证、用户反馈里来回切换。设计师每天被“再出三版方向”“能不能先做个能看就行糙版本”追着跑。运营、HR、财务、法务也一样,所有人都有大量具体、重复、边界清楚但很耗心智的任务。
所以他们拿到 LLM 的第一反应不是“这会重塑组织吗”,而是“这个破事能不能今天少折磨我一点”。
这正是超级个体长出来的土壤。好奇心不是抽象品质,而是被具体问题唤醒的探索冲动。自学能力不是培训证书,而是当晚就去反复试 Prompt,第二天早上 AI Coding 的 Demo 已经连同文档一起悄悄发到了干活群里。自驱力不是绩效表上的标签,而是没有人要求你做,你还是把一个 Agent 工作流搭出来。动手能力不是会写代码而已,而是愿意把调研、脚本、表格、文案、发布和反馈缝成一个能跑的回路。
传统 leader 的世界不同。他们的时间被会议切成半小时,信息以汇报、周报、行业报告、供应商方案和战略会的形式进入。他们看到的不是“这个 Agent 帮我省掉了一小时痛苦”,而是“AI Coding 工具是否影响研发体系”、“是否存在安全风险”、“是否需要统一采购”、“是否应该成立专项小组”。
这些问题都合理,但它们天然慢。
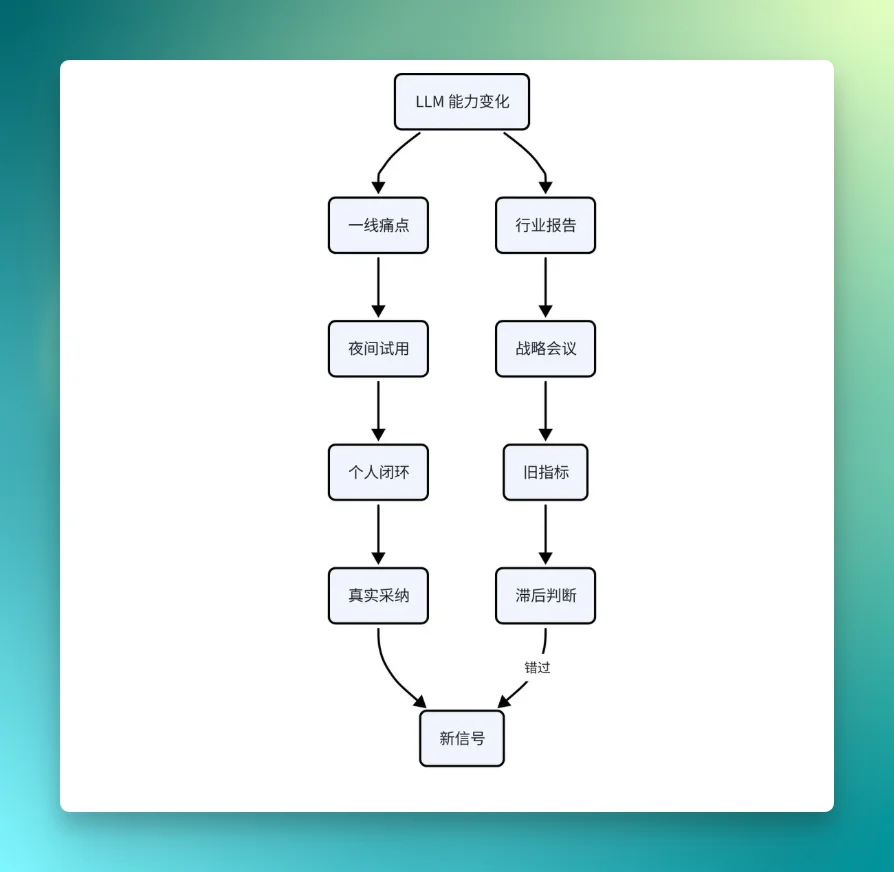
这张图里有一个关键差异:一线员工用身体学习,leader 用材料学习。
LLM、Prompting、AI Coding、Agent 这类东西,最早不是知识,而是“手感”。你不亲自把一个任务交给 Claude Code,不亲自看它读错文件、改坏测试、再被你纠正回来,就很难理解它到底强在哪里、弱在哪里。你不亲自写过很多次失败的 Prompt,就会把 Prompting 误解成“把话说清楚”。你不亲自调度过多个 Agent,就会以为并行只是多开几个窗口。
于是,信息差出现了。
一线员工已经在用 Agent 生成测试、写脚本、做研究、改页面、出 Demo、整理会议纪要。leader 可能还在问:“什么时候上线?”、“你别一个人做,我给你再加 10 个人,可以加速 10 倍吗?”、“这个工具和我们现有平台的定位是什么?”一线员工已经感受到完整的 PMF 已经跑通了,而 leader 还在用岗位效率提升来理解它。
更麻烦的是,旧指标会惩罚探索。
大公司管理者要对稳定性、合规、成本、团队公平、资源分配负责。一个 leader 如果鼓励大家随便试 Agent,出了数据泄露、质量事故、采购浪费,责任在他。如果他不鼓励,只是慢一点,责任反而不清晰。于是组织激励天然偏向“等标准答案出现”。
这也是为什么很多 leader 会把 Early Adopter 误读成“不聚焦”。
你知道吗——Early Adopter 为什么常被误读为“不聚焦”?
因为他们的学习路径看起来不像项目路径。他们今天试 Claude Code,明天试 MCP,后天写一个内部 bot,大后天又把工作流迁到别的工具。在一些人看来这是东一榔头西一棒、憋大招,而在新世界看这是在寻找新的闭环边界。
在旧组织里,探索必须先被翻译成项目,项目必须对应指标,指标必须进入汇报链条。可是 AI 工业革命早期最有价值的探索,恰恰常常没有稳定名字。它一开始不是“平台”,不是“战略”,不是“创新专项”,只是一个员工觉得“这事应该可以自动化”的冲动。
延迟就发生在这个翻译过程里。
一线员工的语言是:我试了一下,它真的能跑。leader 的语言是:这个方向是否值得资源投入。两句话之间隔着一整套旧时代的预算、法务、合规、架构、绩效和职级体系。
所以,大公司如果想激发超级个体,第一步不是号召 leader “拥抱变化”。这种话太轻。
第一步是改变 leader 接收新信号的方式。今天大公司的 leader 们很容易活在 -1 这一层无心(或有意)编织出的信息茧房里,活在小红书、抖音、微信视频的 AI 营销号里。少看一层汇报,多看一次真实 Demo,少问“归哪个部门”,多问“谁已经自发在用”,少用季度 ROI 判断胚胎,多用采纳曲线、复用次数、用户抱怨和任务闭环判断方向。更重要的是,leader 自己要下场使用 LLM、Prompting、AI Coding,有能力的应该自己做几个 Agents,不然他永远只能隔着材料理解工业革命。
延迟不是不可挽救的,但它不会被培训课治好。它只能被新的实践结构治好:让 leader 重新接触一线痛点,让一线 Early Adopter 的小闭环被看见,让那些好奇、自学、自驱、爱动手的人不必先伪装成传统项目经理,才能证明自己正在推动组织往前走。
误判

不容易成为超级个体的人,并不是不聪明。
恰恰相反,他们很多人是高分学生、优秀员工、靠谱骨干。他们习惯先理解体系和原理,先掌握基础知识,先听完课程,先等工具成熟,再开始行动,他们觉得如果一个品类别人做了,自己就不能再做了。这套姿态在过去二十年的组织里非常有效,因为过去的知识结构相对稳定,先学框架、再做项目,是一种高胜率路径。
但 AI 时代有一个麻烦:工具变化得比课程快,产品形态变化得比分类快,真实问题变化得比组织流程快。
于是过去的学习姿态,开始变成新世界的行动阻力。
最典型的第一类,是总想先问分类的人。
他们会问:“Agent 到底分几类?”,“Prompt Engineering 和 Context Engineering 的边界是什么?”,你给我讲讲“AI Coding 工具应该按 IDE、CLI、Plugin 还是 Agent 平台分类?”,“Claude Code 和 Codex 是一种东西?”,这些问题不是没有价值。问题在于,如果分类是行动的前置条件,一个人就会永远等在入口处。
人们习惯了先问分类,超级个体先问能不能用来解决我的问题。
第二类,是总想先找课程的人。
他们希望有一门“系统学习 Agent”的课,最好从概念、历史、工具、案例、最佳实践一路讲完。可是 Agent 这件事本身还在生成过程中,今天的最佳实践,三个月后可能就变成历史包袱。课程能帮人少走弯路,但它不能替代一个人把手伸进泥里。
第三类,是总想先等体系的人。
等公司统一采购,等别人买了 Claude Code Pro/Max 账号后教我,等 IT 开权限,等平台组出规范,等安全部门给白名单,等上级把“AI 提效”写进 OKR。等到所有东西都齐了,窗口也许已经过去了。超级个体不是不管风险,而是会在风险可控的边界里先做一个小闭环,让事实出现。
第四类,是总想先问竞品异同的人。
“这个和 Cursor 有什么区别?”,“Skills 和 Prompt~~(读 Promote)~~有什么区别?”,“这个和飞书已有 AI 功能有什么区别?”,“这个和公司的 AI 路线是否冲突?”这些问题适合产品评审会,却不适合作为探索的第一反应,似乎别人做了,你就不能再做了。很多新东西一开始没有清晰差异,差异是在使用中长出来的。
你知道吗——“如何系统学习 Agent”可能是一个旧世界问题?
它背后的默认假设是:先有一套稳定知识,再有正确行动。但 Agent 的很多知识恰恰来自行动之后。你先让它替你做一次调研、改一次文档、跑一次测试、整理一次用户反馈,失败会比课程更快告诉你边界在哪里。
这不是在鼓励反智,也不是说分类、课程、体系、竞品分析都不重要。它们当然重要,只是位置变了。
在过去,它们是行动之前的安全垫。在新世界里,它们更像行动之后的整理工具。先做一个小东西,先让它碰到真实问题,先得到失败样本,再回头命名、分类、沉淀方法论。这条路径看起来不够体面,但更接近 AI 时代的知识生成方式。
所以“不容易成为超级个体”的真正原因,不是能力弱,而是人格结构没有被行动激活。好奇心被分类延迟,探索精神被课程替代,自学能力被体系外包,自驱力被审批冻结,动手能力被竞品分析消耗。

大公司里大量“先问分类”的人,不是坏人,也不是落后分子。他们只是被过去体系训练得太成功了。一个稳定组织最奖励的,往往就是这种姿态:先对齐,先学习,先写方案,先别乱动。
但超级个体的启动方式刚好相反。
他看见一个问题,会先问:“我能不能今天用 AI 把它往前推一步?”不一定成功,不一定优雅,不一定能立项,但他先让事情动起来。动起来之后,课程才有上下文,分类才有意义,体系才有抓手,竞品差异才会变成真实判断,而不是会议室里的概念游戏。
这就是新旧世界最深的误判:人们以为超级个体掌握了更多知识,新世界真正发生的是,超级个体把知识、工具、问题和反馈重新接成了一个行动闭环。
土壤

超级个体能培养吗?
如果“培养”指的是把一群人拉到会议室里,上一套课,发一张证书,再要求他们按标准流程输出 AI 创新项目,笔者的判断是:很难。
因为超级个体首先不是一组技能包,而是一种底层人格结构。
•好奇心强,好胜心也强
•创新精神强,同时也是别人眼中的 trouble makers
•自学能力强
•自驱力强
•动手能力强
以上这五件事不是超级个体定义的全部,但它们构成了那种人最底层的发动机。组织能做的不是制造人格,而是把这种人格结构放进能闭环的场域里。
问题在于,旧的培训体系最擅长的是传递确定知识,最不擅长的是激发这种发动机。它可以教会一个人什么是 Prompt、什么是 Agent、什么是 Workflow,却很难让一个人突然开始对真实问题发痒,更难让他愿意在没有标准答案的时候自己往前走。
所以更准确的说法不是“培养超级个体”,而是:用组织闭环把超级个体激发出来。
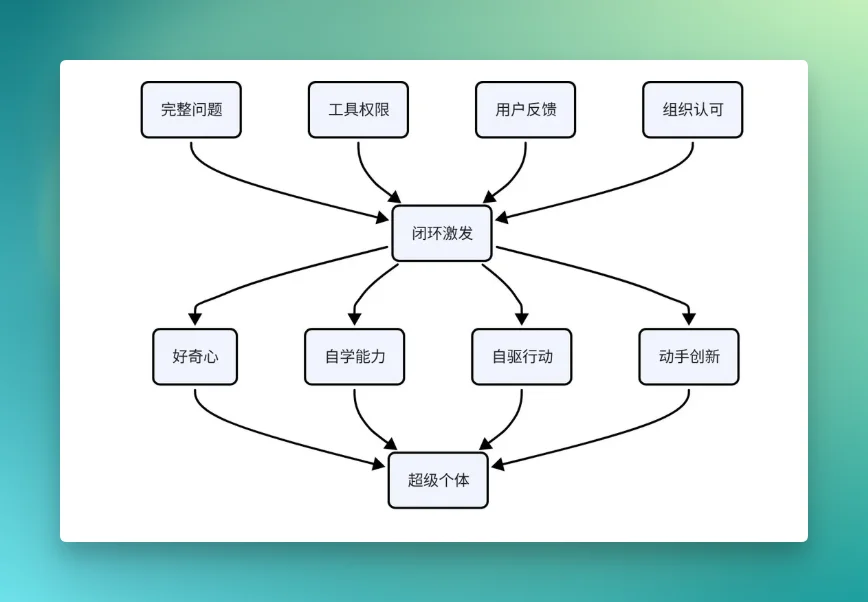
这件事需要四块土壤。
•完整问题所有权:一个人不能只拿到被切碎的任务。他至少要能从问题定义、方案选择、原型验证、用户反馈一路看到后果。没有完整问题,就没有最终责任感。
•工具权限:AI 时代的动手能力,已经不只是会写代码。它还包括调模型、接工具、跑数据、做原型、发灰度、看反馈。组织不给工具权限,就等于让人只用嘴创新。
•直接用户反馈:超级个体不是在汇报链条里长出来的,而是在用户反馈里被打磨出来的。用户的困惑、惊喜、流失和复用,都是比上级评价更真实的训练信号。
•组织认可:组织必须承认“个人痒点”、“非正式原型”、“先做出来看看”、“Fail faster, fail earlier”是合法工作,而不是边角料、爱好和不务正业。
把它画成一张图,大概是这样:
这也是为什么在很多组织里,产品经理、设计师、前端工程师,反而比一些更“懂模型”的角色更容易先长出超级个体。
产品经理天然靠近问题定义,知道用户为什么卡住。设计师天然靠近体验细节,能感受到一个产品形态是不是成立。前端工程师天然靠近可交互原型,今天有一个想法,晚上就能把能点的 Demo 做出来。
这三类人有一个共同点:他们离完整闭环比较近。
他们不一定最懂 Transformer,不一定能解释 LoRA 和 MoE 的差别,但他们能快速把 AI 能力接到一个具体工作流里:让一个报表自动生成,让一个客服流程少走三步,让一个内部知识库能被自然语言调度,让一个新功能先以半成品方式被用户摸到。
模型论文解决“能力能不能出现”,产品形态解决“能力能不能被人使用”。工作流解决“能力能不能反复改变人的行为”。超级个体往往最先站在后两者的交界处。
你知道吗——懂模型不等于看见产品?
懂模型的人,往往能判断一个能力的技术边界。看见产品的人,能判断这个能力应该嵌进谁的哪一个动作里。前者回答“模型能做什么”,后者回答“人会不会因此改变工作方式”。AI 时代真正稀缺的,常常是第二种眼睛。
所以大公司如果真想“培养超级个体”,第一反应不应该是做一套 AI 学院课程。课程可以有,但它只是肥料,不是土壤。
更关键的是问四个组织问题:这个人有没有完整问题?有没有工具权限?能不能直接看见用户反馈?组织会不会认可他在正式岗位之外长出的新能力?
如果四个答案都是没有,那么再多培训也只是在旧岗位上贴 AI 标签。
如果四个答案慢慢变成有,好奇心会自己找问题,自学能力会自己补知识,自驱力会自己跨边界,动手能力会自己把想法变成原型。到那时,所谓“超级个体”不是被讲师教出来的,而是被逼出来、养出来、照亮出来的。
结语
如果前面几章的判断成立,结论并不是“组织会被个体替代”。
恰恰相反,超级个体不是分工的终点,而是新分工的起点。
旧分工把一个完整的人切成岗位:产品经理负责需求,设计师负责体验,工程师负责实现,测试负责质量,运营负责增长,客服负责响应,财务负责结算,管理者负责协调。它的优势是稳定、可规模化、可替换;它的问题是,人的完整闭环被拆得太碎,最终责任感也被层层摊薄。
AI 之后,分工没有消失,只是尺度变小了。
一个人身边可以站起一组 Agent:有的负责调研与数据,有的负责设计与原型,有的负责编码与测试,有的负责运营、客服与财务整理。过去需要一个小组才能完成的动作,现在会被压缩到一个人的工作台上。
但请注意,真正关键的不是 Agent 变多,而是人重新站回最终责任人的位置。
这个人的角色会越来越像创始人、FDE[1]、产品负责人和 DRI 的混合体。他不一定亲手做每一个动作,但他要定义问题,判断方向,选择工具,验收结果,承担后果。他的好奇心决定问题从哪里开始,他的探索精神决定边界能不能被推开,他的自学能力决定工具变化时会不会掉队,他的自驱力决定无人安排时是否仍然行动,他的动手能力决定想法会停在 PPT 里,还是长成一个能被用户触摸的原型。
这五个特质不是超级个体的全部定义,但它们构成了超级个体的底层人格结构。没有它们,AI 只会把人变成更快的执行者;有了它们,AI 才可能把人放大成新的组织单元。
你知道吗——`Think different` 的组织含义?
回到开头 Apple 那支广告常被读成个人主义宣言。笔者更愿意把它读成组织提醒:那些 misfits、rebels、troublemakers,价值不在反叛本身,而在于他们经常先看见新组合。组织要问的不是如何把他们磨圆,而是如何给他们一个能负责到底的闭环。
所以超级个体不会让大公司失去意义,“一人公司”和“大公司”会长期并存。
大公司手里还握着一人公司拿不到的东西:品牌信用、分发渠道、算力资源、安全边界、合规能力、复杂客户、长期资本、跨专业协作网络。问题是,这些资源一旦被旧岗位、旧职级、旧汇报链条锁住,就从杠杆变成了重量。
真正的挑战只有一个——能不能把这些资源重新接到更小的闭环上。
不是让超级个体在层层审批里证明自己配得上授权,而是默认交给他一块可控的地盘,连同完整问题、工具权限、用户反馈和组织认可一起。不是等一个想法长成大项目才被看见,而是在它还是玩具、Demo、内部脚本、半成品 Workflow 的阶段,就允许它被真实使用、真实反馈、真实淘汰。
错位已经发生了。
一个产品经理已经能调度 Agent 跑调研、用 AI Coding 做原型、写说明、整理访谈,组织却还把他当“需求文档生产者”;一个前端工程师已经能从用户问题一路做到产品 Demo、灰度实验和数据复盘,组织却还盯着他的“代码产出量和”、“需求负载率”;一个设计师已经能用 AI 把交互、文案、页面、动效和用户测试串成闭环,组织却还让他在流程末端美化界面。
原先的尺子量不出新的杠杆,旧的分工框不住新的产能。这才是真正要回答的问题——生产关系本身。
工业化大公司曾经把复杂协作压进岗位、流程和层级里,那是过去的伟大成就。AI 时代要做的不是把它砸碎,而是把它重新组合到“人 + Agent + 组织资源”这个新单元里。
超级个体不是天生的,也不是培训班批量制造出来的。他在完整闭环里被激发,在真实问题里被打磨,在组织认可里被放大。
下一代组织的分水岭,不在谁拥有更多 AI 工具或 Agent,而在谁更早承认:人正在以更小的尺度重新组织生产。

参考资料
[0] Henry:https://xhslink.com/m/AyUHaIeXWic
[1]FDE——AI 时代的职业转型已经打响?:https://my.feishu.cn/wiki/LiubwwOU4iqbS4kxn4EcikHGnTf
[2]Think different campaign:https://www.computerworld.com/article/1629859/the-untold-story-behind-apple-s-think-different-campaign.html
[3]Find a Position of Leverage:https://www.navalmanack.com/almanack-of-naval-ravikant/find-a-position-of-leverage
[4]新浪科技旧文:https://tech.sina.com.cn/c/2001-08-24/5372.html
[5]界面新闻回顾:https://www.jiemian.com/article/4178068.html
[6]FlashGet 十周年大事记:https://www.flashget.com/10th/
[7]WinZip 的 Nico Mak Computing 回顾:https://www.winzip.com/en/learn/old-brands/nico-mak-computing/
[8]ACDSee About:https://www.acdsee.com/en/about/
[9]TechSpot 的 Winamp 回顾:https://www.techspot.com/article/2042-winamp/
[10]在 2002 年写了自己第一个破万的 Shareware —— MagicCube Lyric Editor:https://web.archive.org/web/20030816005420/
[11]*How Do Committees Invent?*:https://inigomedina.co/library/work/conway-law
[12]ChatGPT:https://openai.com/blog/chatgpt/
[13]Pragmatic Engineer:https://newsletter.pragmaticengineer.com/p/how-claude-code-is-built
[14]OpenClaw:https://openclaw.ai/
文章来自于"十字路口Crossing",作者 "Henry[0](DeerFlow团队)"。
【开源免费】ai-renamer是一个用AI帮你做文件夹或者图片命名的项目。该项目会根据文件夹或者图片内容来为文件进行重新命名,让你的文件管理更加便利。
项目地址:https://github.com/ozgrozer/ai-renamer
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

